How AI reads GitHub
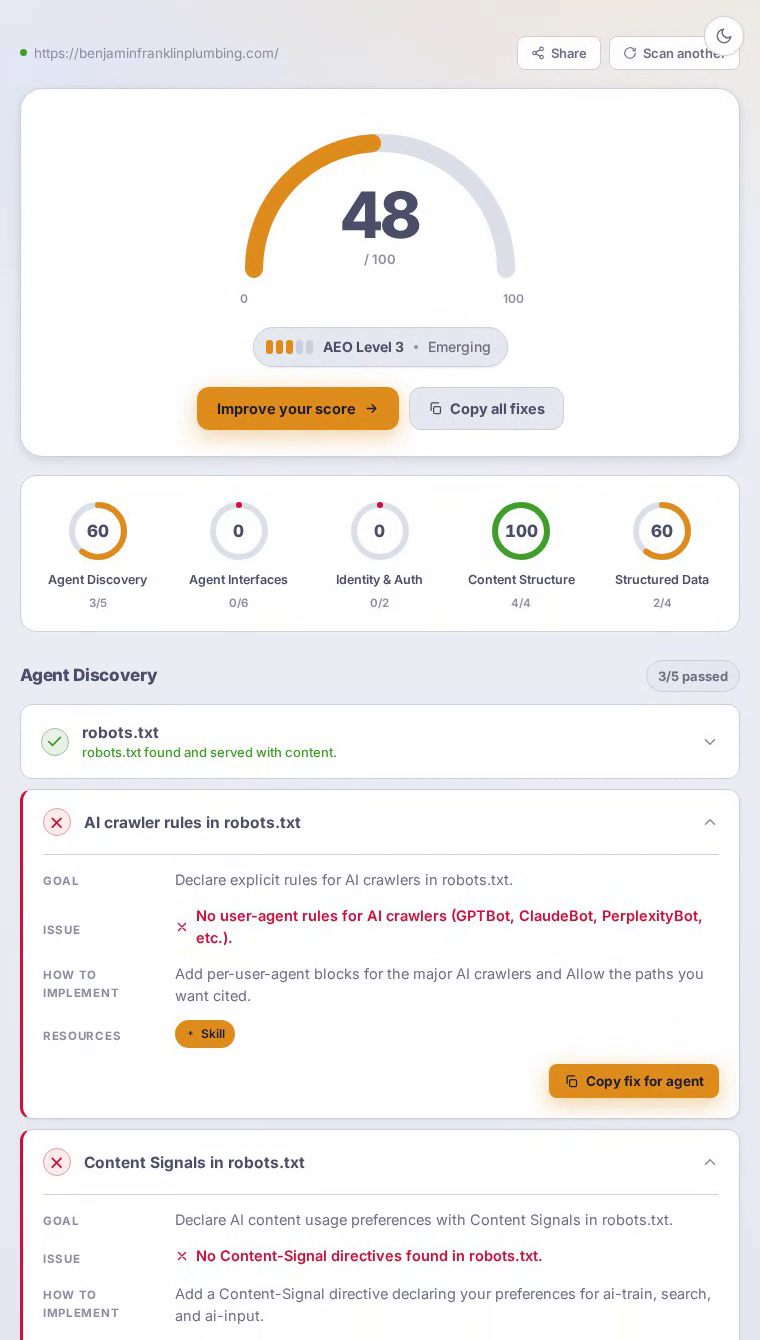
GitHub scores 18 out of 100 on our AEO scan — meaning AI agents and answer engines have almost no structured entry points into the platform. Despite hosting hundreds of millions of repositories, the world's largest developer community is nearly invisible to autonomous AI agents.
What AI sees
When an AI agent visits GitHub's homepage today, it lands on a JavaScript-heavy marketing surface with virtually no machine-readable discovery signals in place.
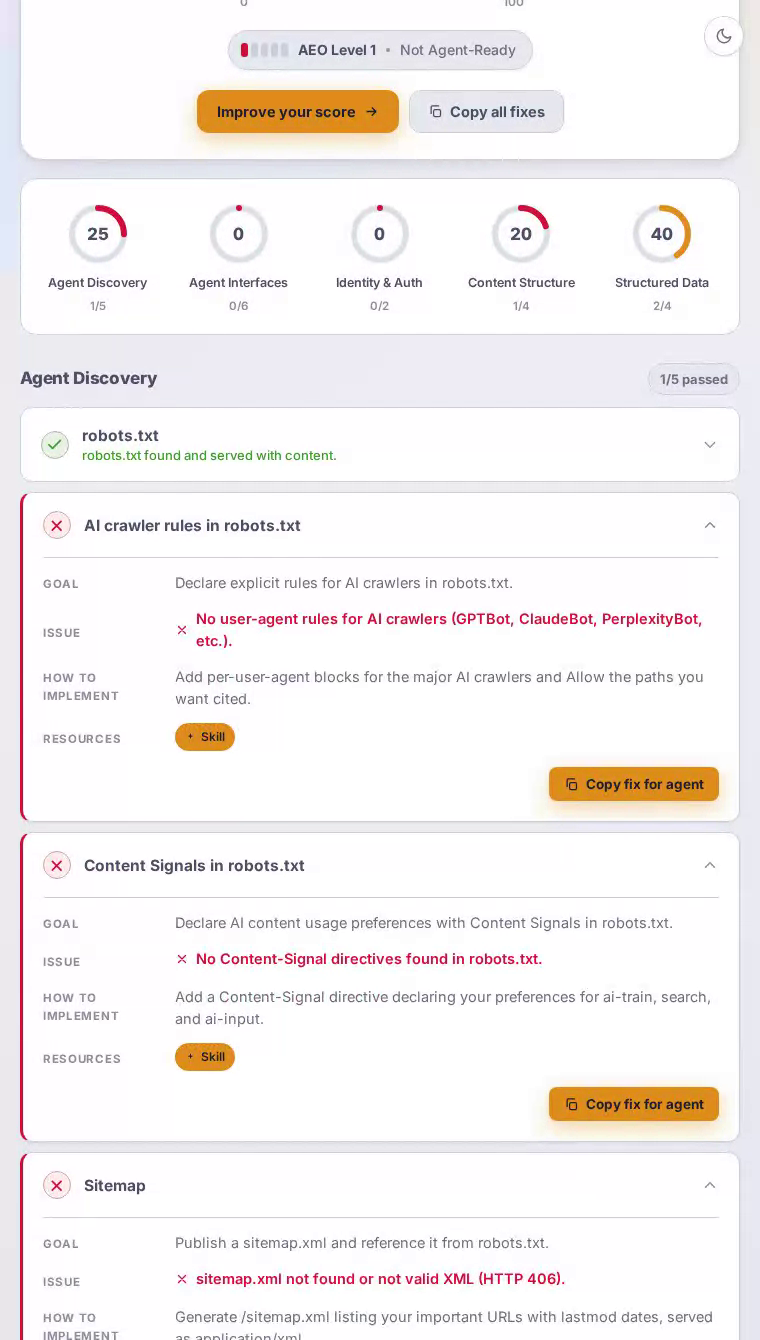
An AI crawler hitting GitHub's homepage receives a mostly client-side-rendered shell. The structured data score of 40 suggests some schema markup exists — likely for organization identity — but a content_structure score of 20 means the actual page content is poorly segmented for machine consumption. There are no Link response headers pointing agents toward APIs, MCP endpoints, or agent-facing resources. The robots.txt file contains no per-crawler rules for GPTBot, ClaudeBot, or PerplexityBot, so AI agents operate in a rules vacuum. Critically, agent_interfaces scores 0: no MCP Server Card, no API catalog at the well-known path, and no Markdown fallback — so agents that prefer structured ingestion find nothing to latch onto.
Where it loses points
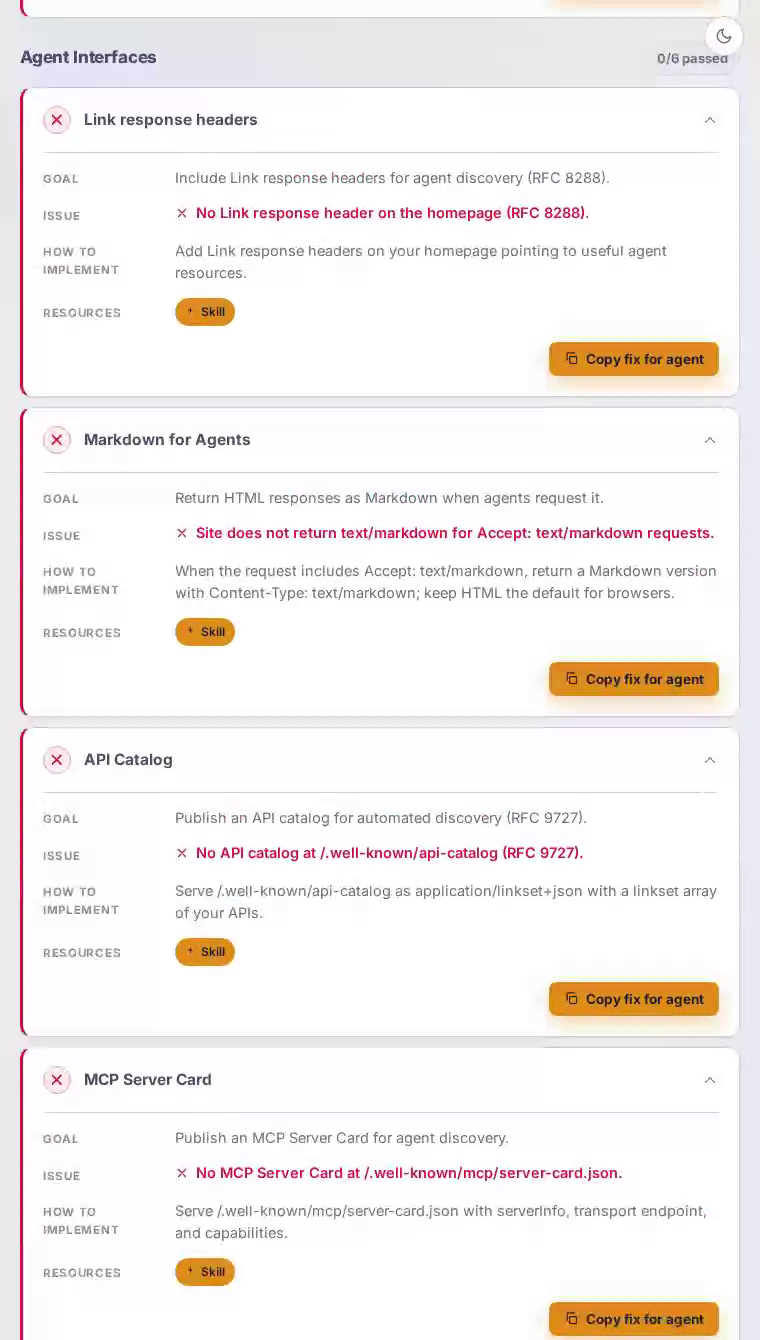
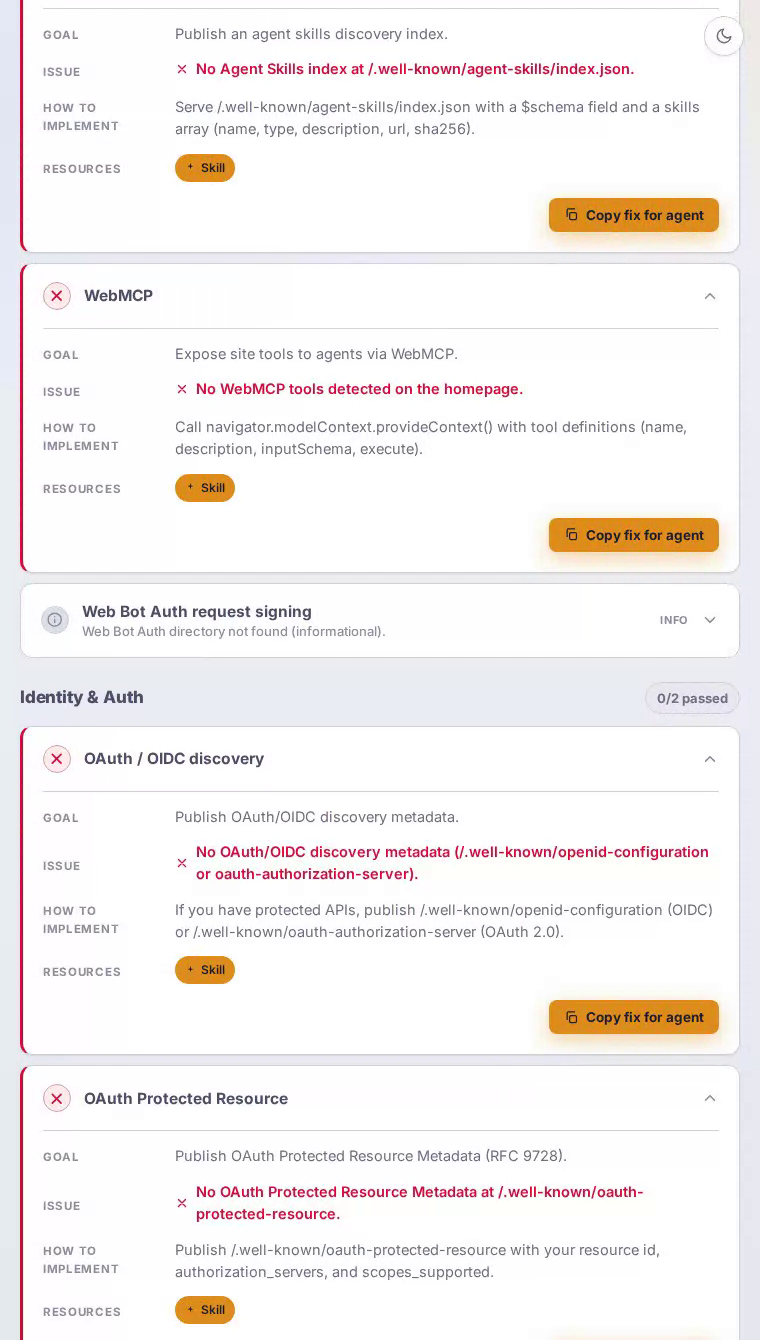
Agent interfaces is the weakest category at 0/100 — a striking gap for a platform whose entire value proposition is programmatic, developer-driven access.
How to fix it
Three targeted changes would close the most consequential gaps between GitHub's current AEO posture and the baseline AI agents expect before interacting with any platform.
Declare AI crawler rules in robots.txt
Give GPTBot, ClaudeBot, PerplexityBot, and peer crawlers explicit permission rules so they know exactly which paths to index and which to avoid.
The scan found no per-user-agent directives for any major AI crawler — every bot operates on inherited wildcard rules designed for traditional search engines, not autonomous agents.
Add named User-agent blocks for GPTBot, ClaudeBot, PerplexityBot, and OAI-SearchBot. Under each, Allow paths like /topics/, /explore/, and public repository roots while Disallowing authenticated API routes and private endpoints.
Publish an MCP Server Card
Register GitHub as a discoverable agent tool by serving a machine-readable MCP Server Card at the canonical well-known path so agents can auto-discover and authenticate against its capabilities.
Nothing is served at /.well-known/mcp/server-card.json, so AI agents that auto-discover tools via the Model Context Protocol cannot find GitHub's officially maintained MCP server.
Serve /.well-known/mcp/server-card.json with serverInfo (name, version, description), a transport endpoint pointing to the GitHub MCP server, and capabilities listing repositories, issues, pull-requests, and code-search — the server already exists, the card simply makes it auto-discoverable.
Publish an RFC 9727 API Catalog
Expose a machine-readable index of GitHub's REST and GraphQL APIs so agents can discover and call them without relying solely on training data.
No resource is served at /.well-known/api-catalog, leaving agents unable to programmatically discover GitHub's extensive API surface through the standard RFC 9727 mechanism.
Serve /.well-known/api-catalog as application/linkset+json with entries for the REST API v3 base, the GraphQL endpoint, and the Copilot Extensions API, each including anchor, rel, type, and title fields per RFC 9727 so agents can resolve capabilities at runtime.
Common questions
Why does GitHub score only 18/100 on AEO despite having a massive public API?
Does GitHub's low AEO score mean AI assistants cannot access repository data?
What is the fastest single fix GitHub could make to improve its AEO score?
Is your own site ready for AI?
Run the same five-category analysis on any URL. Free, no account needed to start.
Check your own website free