AI 如何读取 Notion
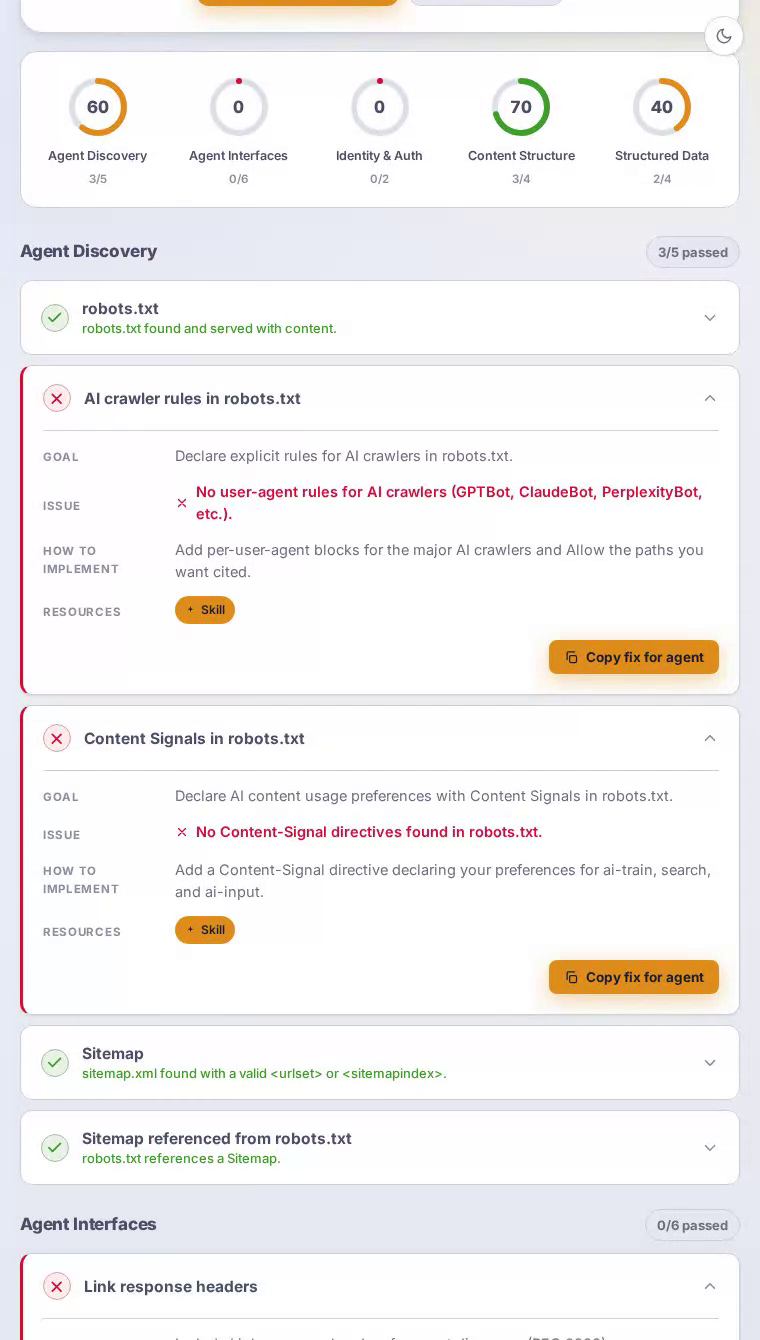
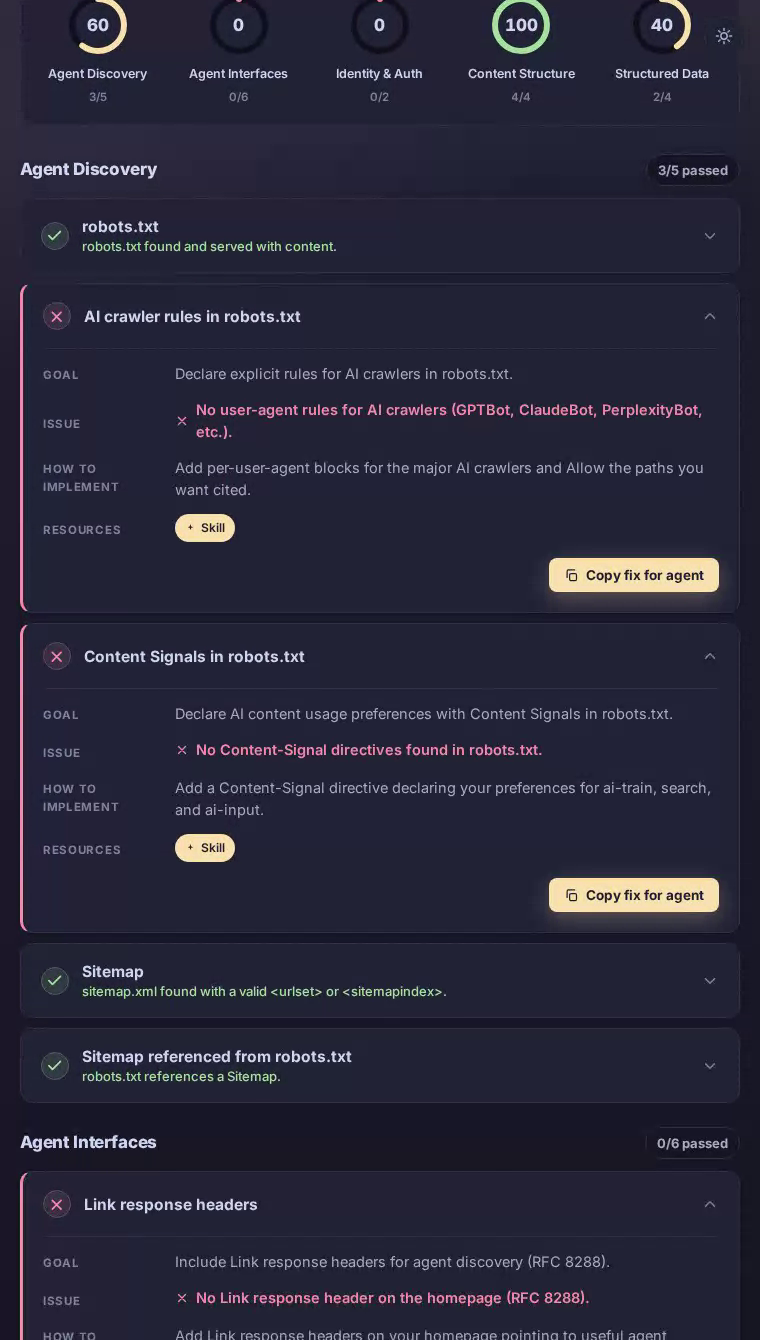
Notion在我们的AEO扫描中得分43/100——一个明显分化的结果。内容结构达到完美的100分,因此AI可以清楚地解析主页。但代理接口和身份认证都得分为零,这使AI助手无法发现或使用Notion的整个开发者生态系统所围绕的API。
AI 看到了什么?
AI代理访问Notion主页会发现干净、可解析的文本——以及几乎没有其他它能操作的内容。
主页提供了结构良好的HTML和明确的内容层次,这就是为什么content_structure达到完美的100分。AI可以识别Notion是什么、提取其价值主张,并有高度信心地总结产品。问题从代理尝试深入发展的那一刻开始。robots.txt中没有GPTBot或ClaudeBot等AI爬虫的明确规则,没有指向有用资源的Link响应头,尽管Notion提供了广泛使用的公共REST API,却没有API目录文档。一个整个价值主张都是结构化信息的生产力平台,却几乎完全没有填充自己面向代理的信息层。
它在哪里丢分?
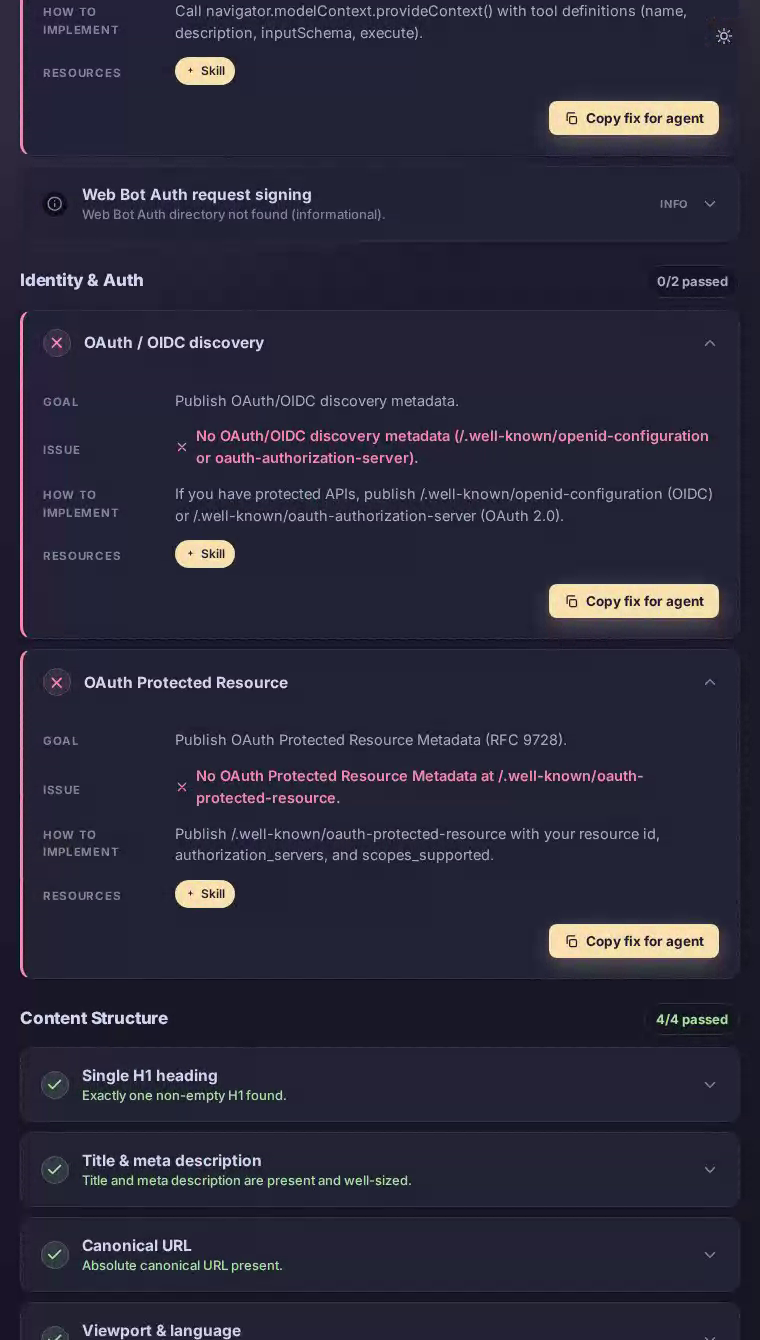
代理接口和身份认证都得分为零——对于电源用户生活在集成和自动化中的平台来说,这很令人注目。
该如何修复?
三个针对性的改变,都可以在不触及Notion产品代码的情况下实现,将解锁这个平台已经在架构上准备好的代理层。
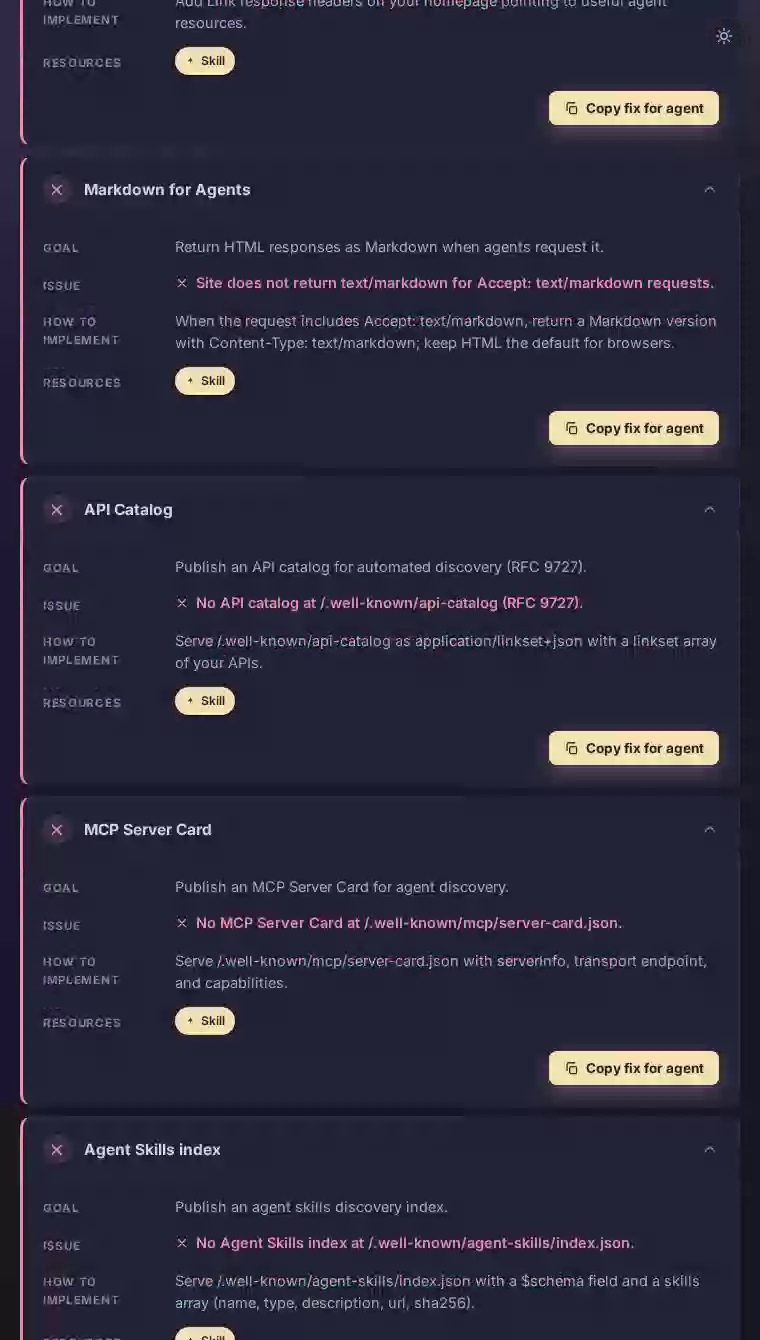
发布MCP Server Card
通过Model Context Protocol将Notion公开为AI代理的一流工具源。
在/.well-known/mcp/server-card.json处不存在MCP Server Card,因此代理无法发现或连接到Notion的功能。
在/.well-known/mcp/server-card.json处提供包含serverInfo块、指向Notion API网关的传输端点和涵盖页面读取、数据库查询和块编写的功能列表的内容。这个单一文件允许任何兼容MCP的代理将Notion视为本地工具,无需自定义配置。
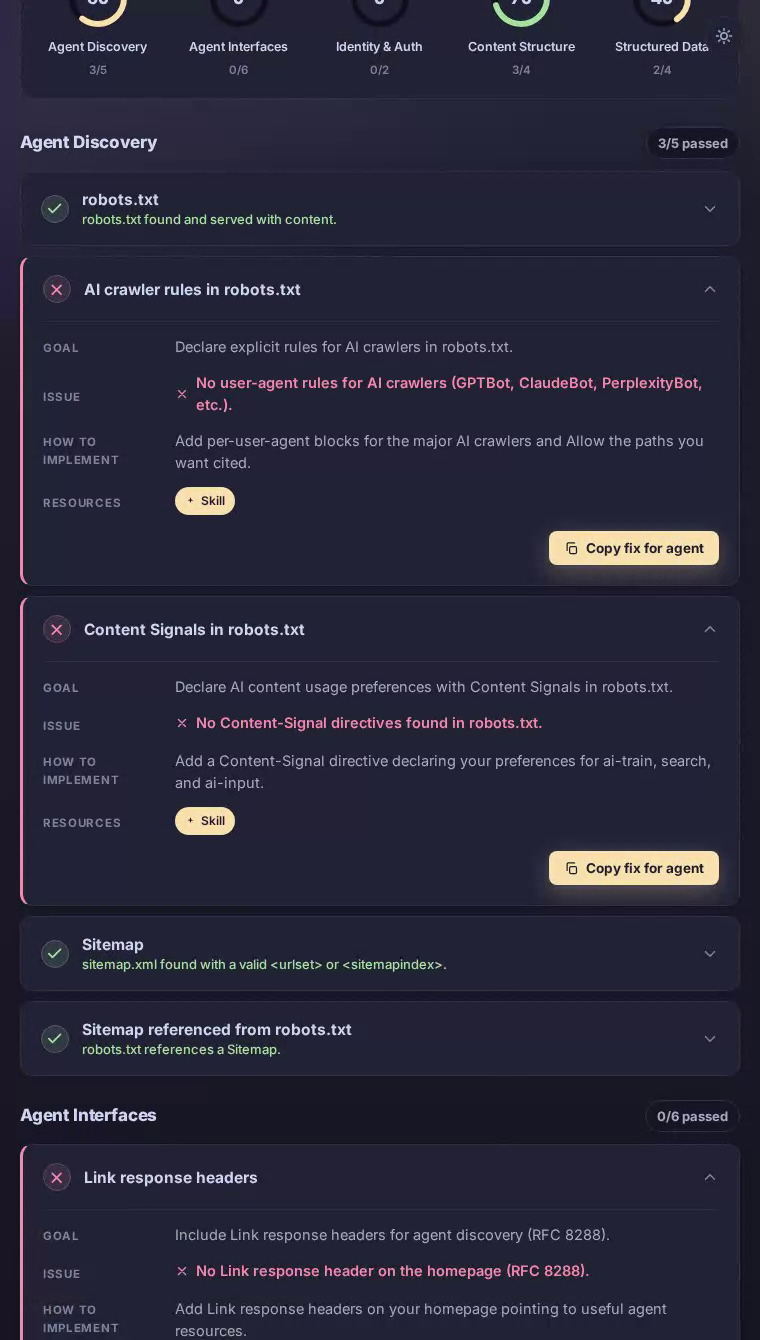
在robots.txt中声明AI爬虫规则
为AI爬虫提供明确的权限信号,以便Notion的公共内容按Notion自己的意愿被准确索引。
Notion的robots.txt不包含GPTBot、ClaudeBot、PerplexityBot或任何其他主要AI爬虫的user-agent规则。
为每个主要AI爬虫user-agent添加显式Allow或Disallow段落,然后是Content-Signal指令,声明对ai-train、search和ai-input的偏好。这关闭了歧义差距,确保引用引擎按意图处理Notion的公共帮助文档和营销页面。
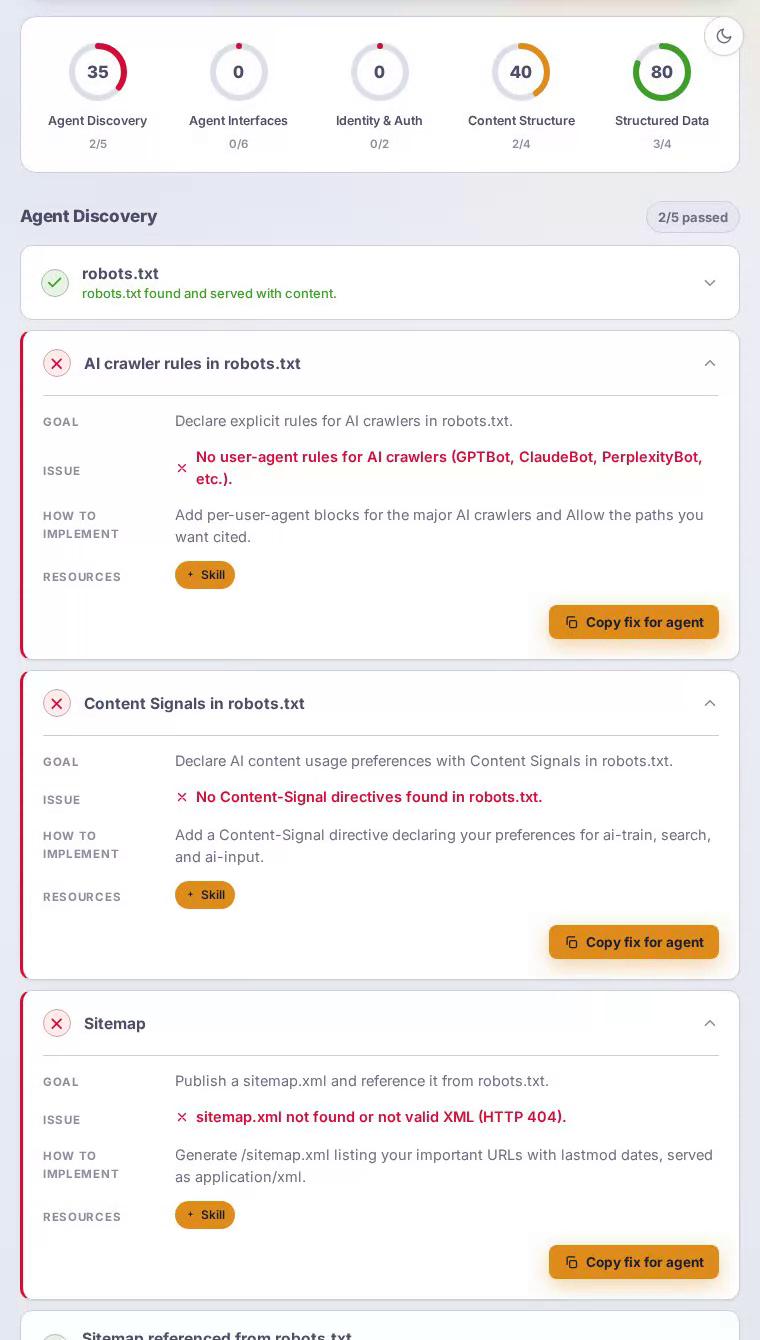
在/.well-known/api-catalog处提供API Catalog
使Notion的公共REST API由遵循RFC 9727的代理自动发现。
尽管拥有成熟的面向开发者的REST API,但在标准well-known路径处没有api-catalog文档。
将/.well-known/api-catalog发布为application/linkset+json,包含每个主要API表面的条目——页面、数据库、块、用户和搜索。遵循RFC 9727的代理将发现并集成Notion的API,无需依赖手动维护的连接器库作为中介。
常见问题
如果Notion的内容结构是完美的,为什么它的得分是43/100?
零agent_interfaces得分在实践中对Notion用户意味着什么?
缺失的robots.txt AI爬虫指导是否会使Notion的内容处于风险中?
你自己的网站为 AI 做好准备了吗?
对任意网址运行同样的五类别分析。免费,开始无需注册。
免费检测你的网站