How AI reads Notion
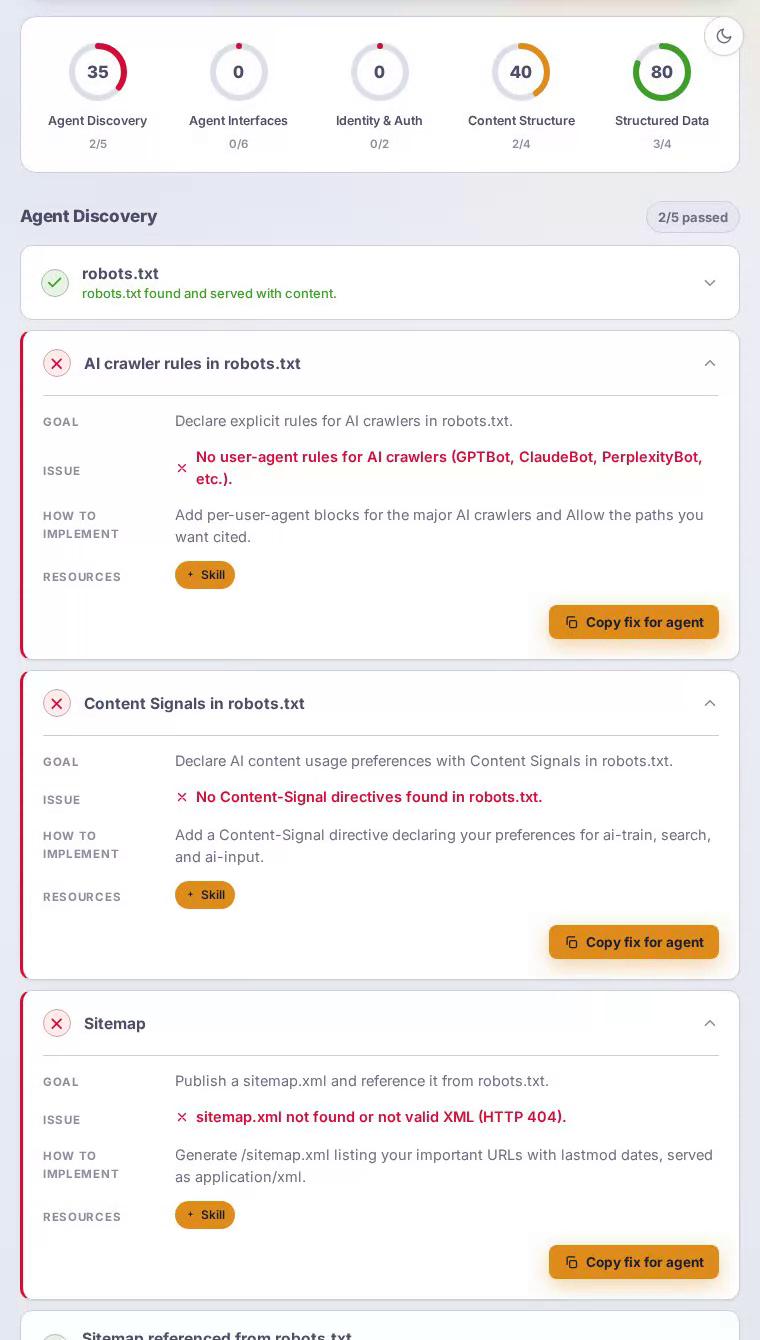
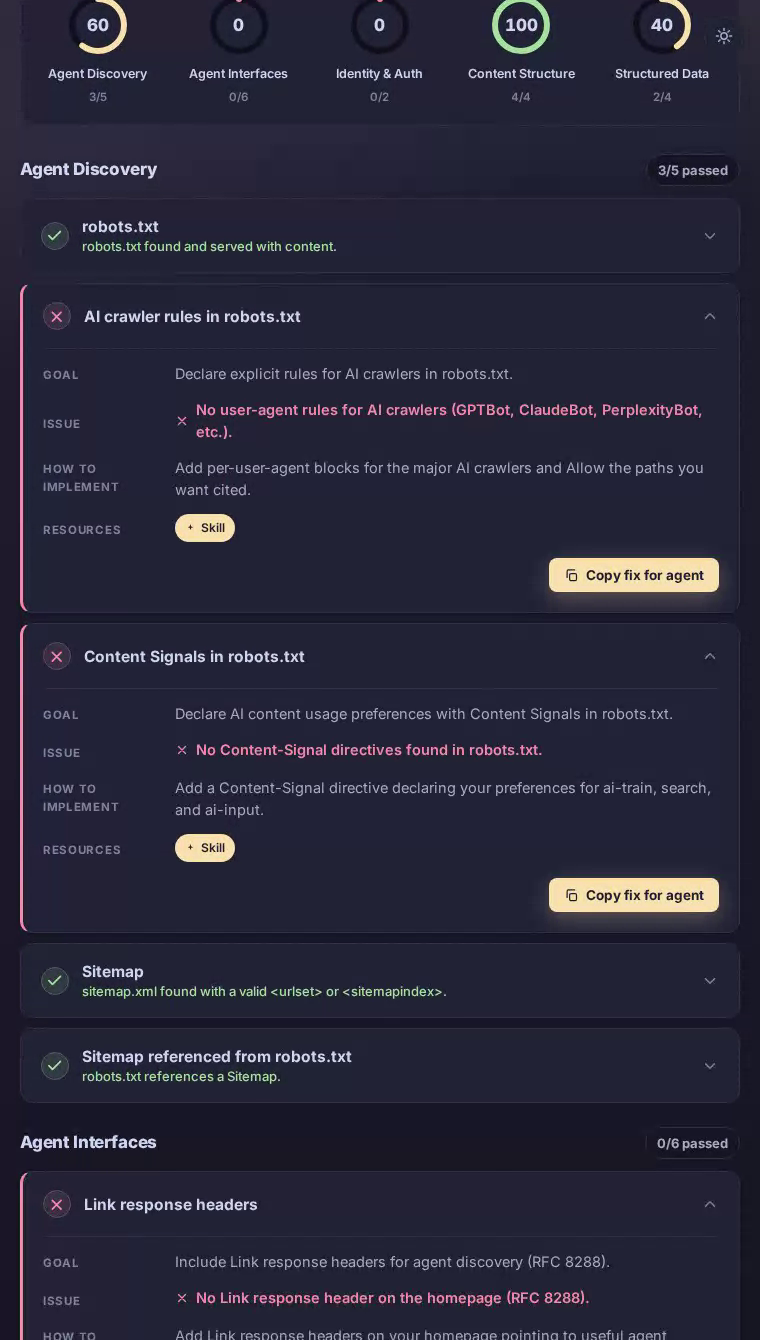
Notion scores 43/100 on our AEO scan — a sharply divided result. Content structure hits a perfect 100, so AI can parse the homepage clearly. But agent interfaces and identity authentication both score zero, leaving AI assistants unable to discover or use the very API that Notion's developer ecosystem is built around.
What AI sees
An AI agent landing on Notion's homepage finds clean, parseable prose — and almost nothing else it can act on.
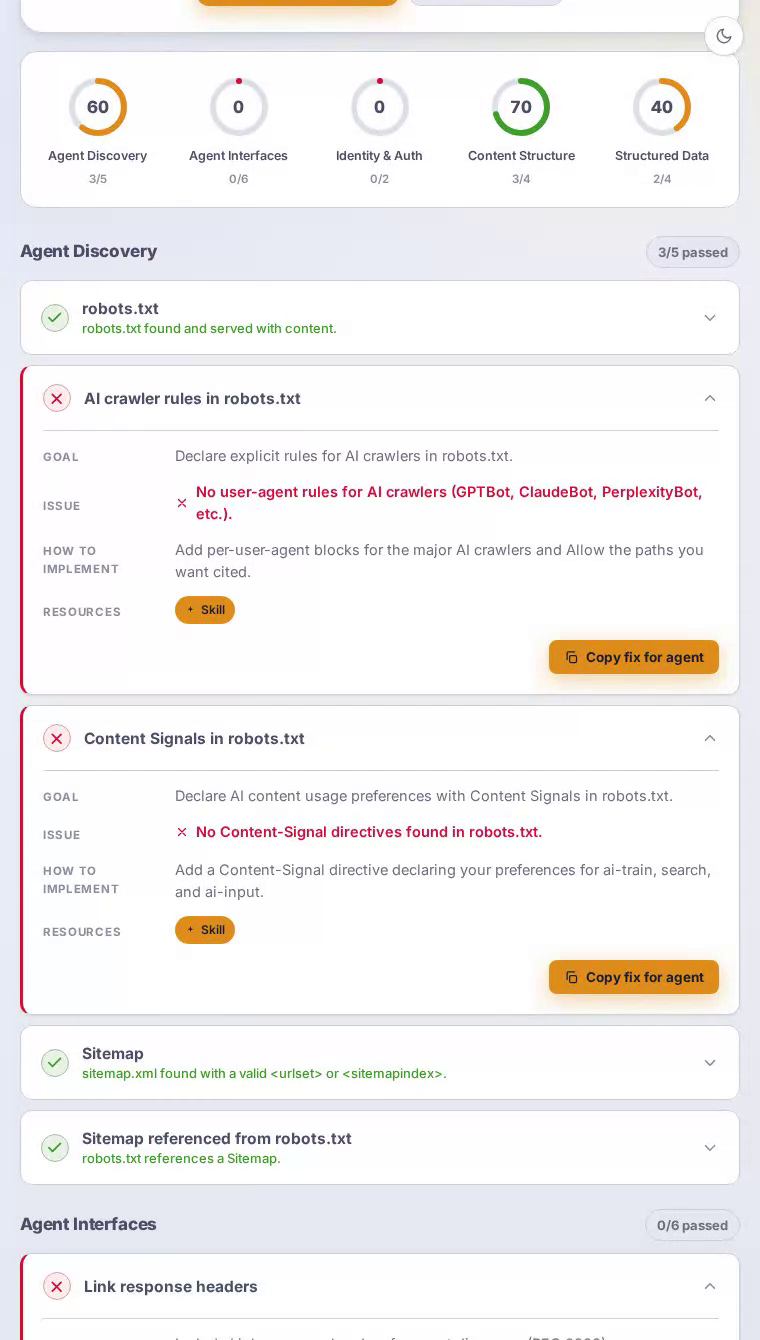
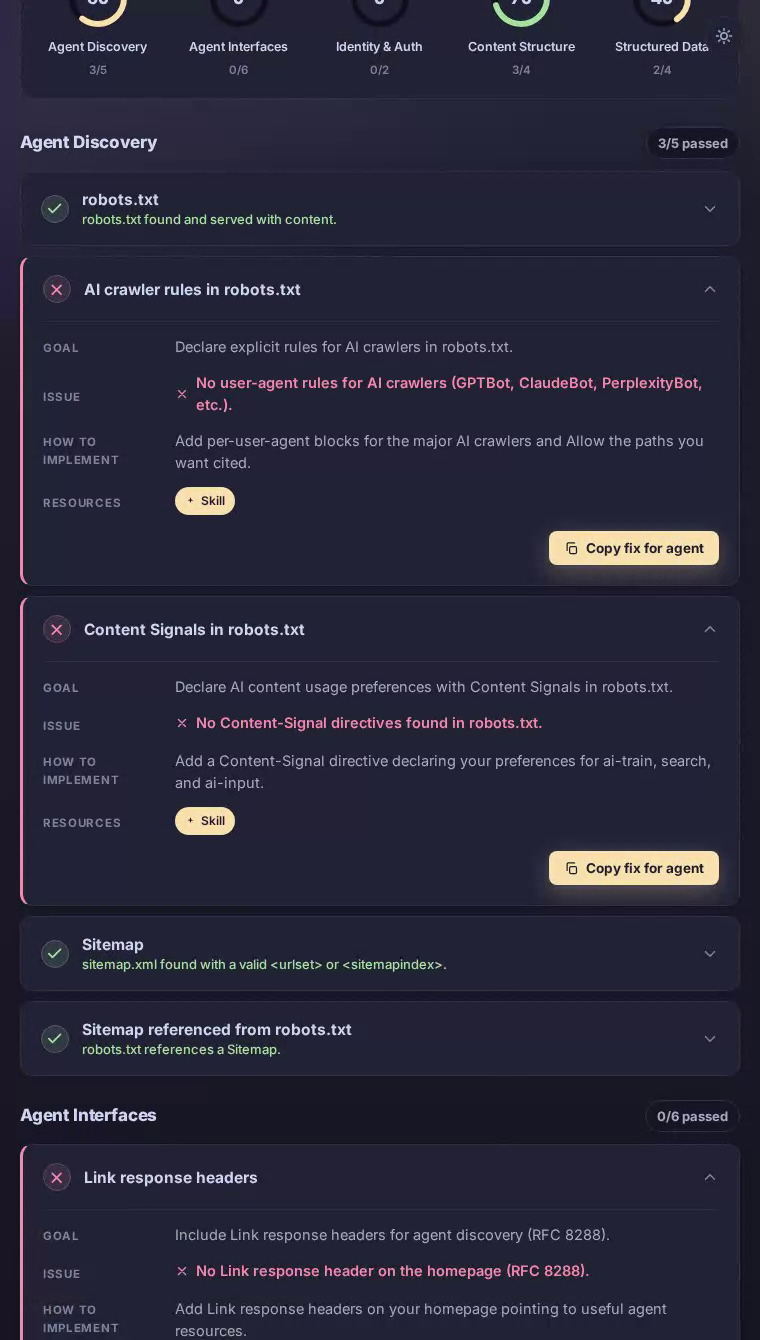
The homepage delivers well-structured HTML with an unambiguous content hierarchy, which is why content_structure reaches a perfect 100. An AI can identify what Notion is, extract its value propositions, and summarize the product with high confidence. The trouble starts the moment that agent tries to go further. There are no explicit rules in robots.txt for AI crawlers like GPTBot or ClaudeBot, no Link response headers pointing to useful resources, and no API catalog document despite Notion shipping a widely-used public REST API. A productivity platform whose entire value proposition is structured information leaves its own agent-facing information layer almost completely blank.
Where it loses points
Agent interfaces and identity authentication both score zero — striking for a platform whose power users live inside integrations and automations.
How to fix it
Three targeted changes, all achievable without touching Notion's product code, would unlock the agentic layer this platform is already architecturally ready for.
Publish an MCP Server Card
Expose Notion as a first-class tool source for AI agents via the Model Context Protocol.
No MCP Server Card exists at /.well-known/mcp/server-card.json, so agents cannot discover or connect to Notion's capabilities.
Serve /.well-known/mcp/server-card.json with a serverInfo block, a transport endpoint pointing to Notion's API gateway, and a capabilities list covering page reading, database querying, and block writing. This single file lets any MCP-compatible agent treat Notion as a native tool without custom configuration.
Declare AI crawler rules in robots.txt
Give AI crawlers explicit permission signals so Notion's public content is indexed accurately and on Notion's own terms.
Notion's robots.txt contains no user-agent rules for GPTBot, ClaudeBot, PerplexityBot, or any other major AI crawler.
Add explicit Allow or Disallow stanzas for each major AI crawler user-agent, followed by a Content-Signal directive declaring preferences for ai-train, search, and ai-input. This closes the ambiguity gap and ensures citation engines treat Notion's public help docs and marketing pages as intended.
Serve an API Catalog at /.well-known/api-catalog
Make Notion's public REST API automatically discoverable by agents following RFC 9727.
Despite a mature, developer-facing REST API, there is no api-catalog document at the standard well-known path.
Publish /.well-known/api-catalog as application/linkset+json with entries for each major API surface — pages, databases, blocks, users, and search. Agents following RFC 9727 will find and integrate Notion's API without relying on manually maintained connector libraries as an intermediary.
Common questions
Why does Notion score 43/100 if its content structure is perfect?
What does a zero agent_interfaces score mean for Notion users in practice?
Does the missing robots.txt AI crawler guidance put Notion's content at risk?
Is your own site ready for AI?
Run the same five-category analysis on any URL. Free, no account needed to start.
Check your own website free