AI 如何读取 Notion
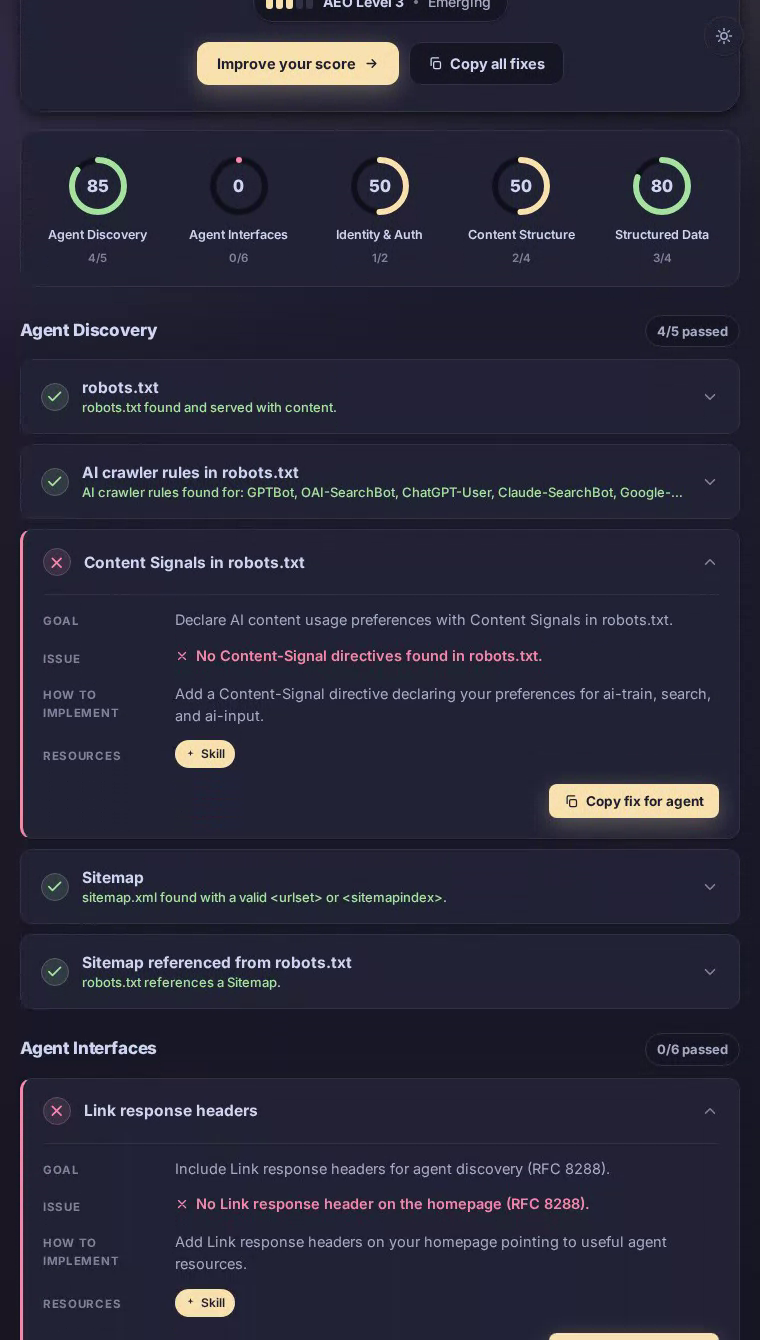
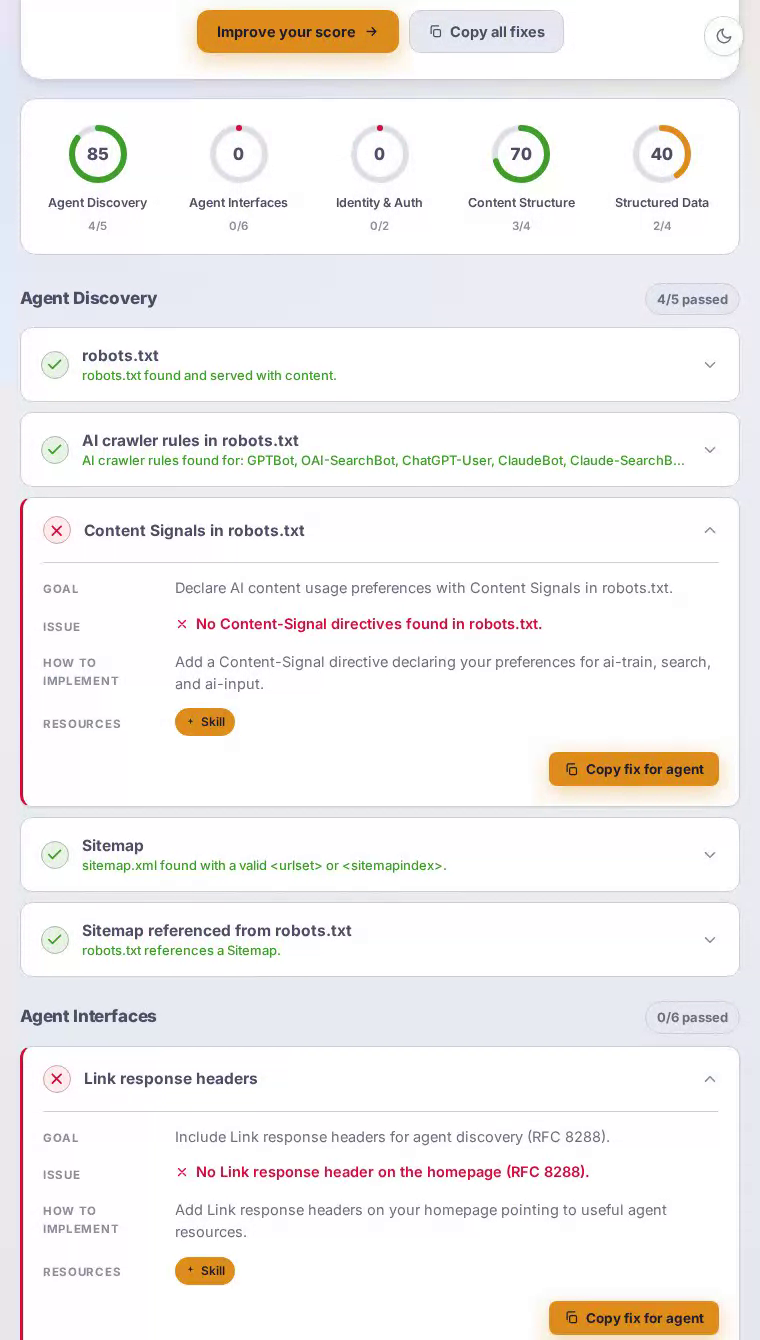
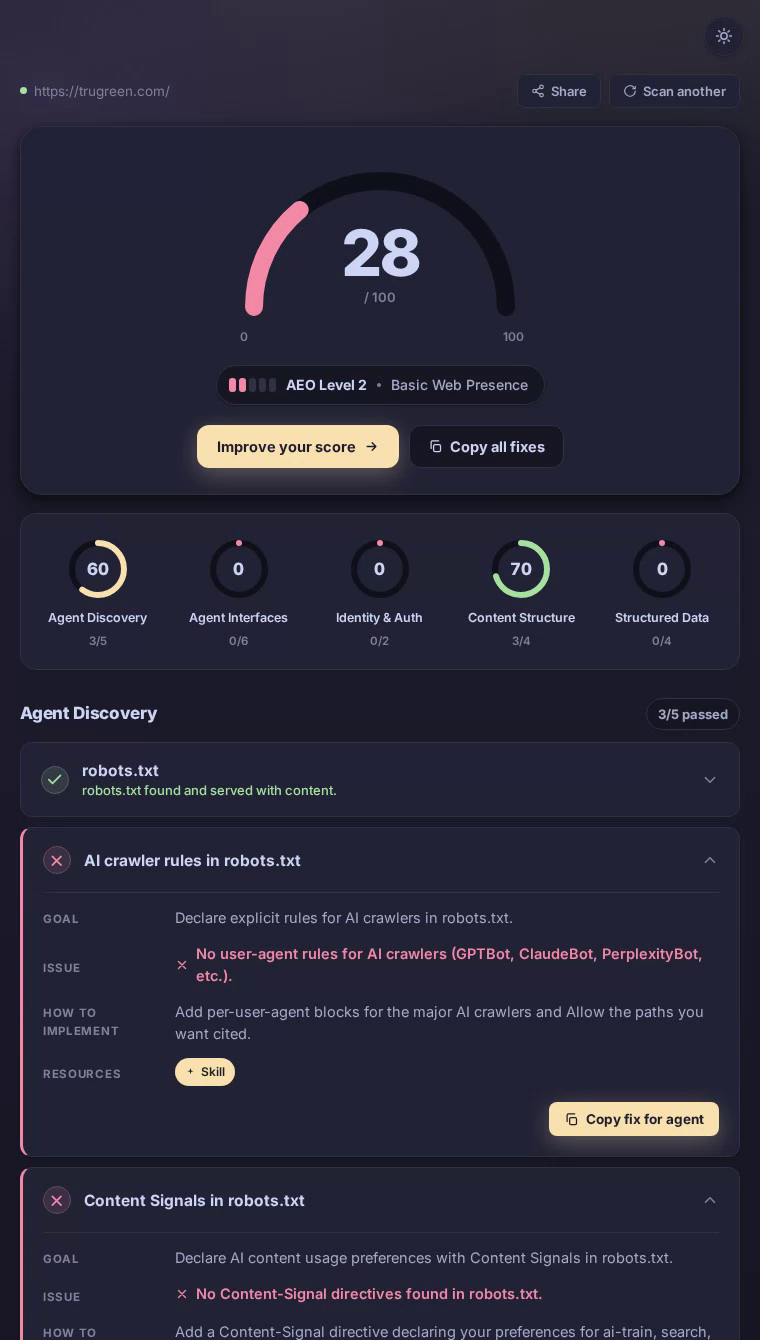
Notion在我们的AEO扫描中获得43/100分——一个中点结果,体现了完美的内容结构但缺乏代理接口支持。该平台的工作区和协作功能写得很好,但今天访问的AI代理找不到MCP服务器卡、robots.txt中没有AI爬虫规则,也没有机器可读的发现端点。
AI 看到了什么?
当AI代理今天访问Notion主页时,它进入内容丰富的区域,在结构上评分完美,但立即遇到协议死胡同。
Notion主页提供了干净的、语义丰富的HTML,具有明确定义的标题,涵盖工作区组织、团队wiki和项目跟踪——内容LLM可以高保真度总结,解释了完美的content_structure评分100。但代理体验在协议边界处迅速恶化。robots.txt不包含GPTBot、ClaudeBot或PerplexityBot的针对代理的指令,让爬虫推断权限。主页上没有Link响应头来引导autonomous客户端发现APIs或结构化资源。标准代理发现端点都不存在——API目录、MCP服务器卡、agent技能索引。对于一个完全围绕结构化信息而构建的产品来说,这种沉默是一个明显的错失。
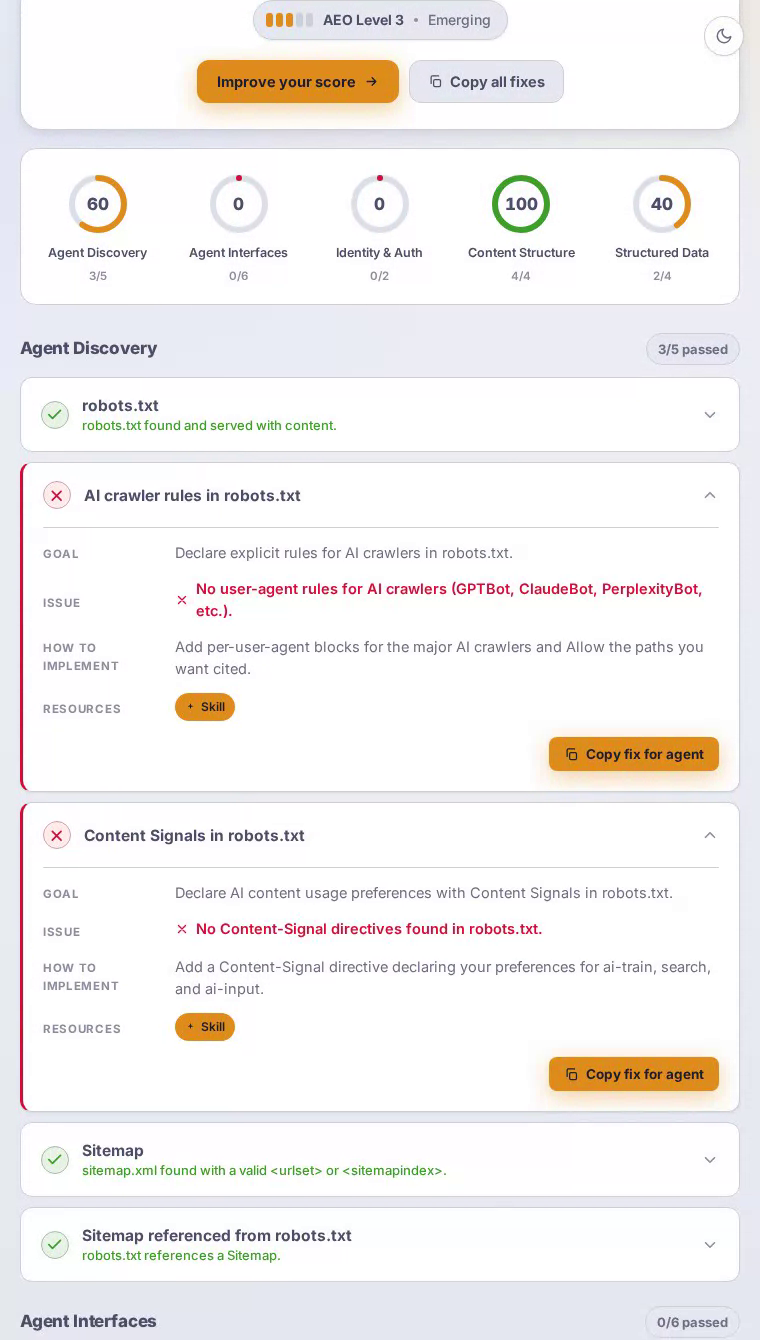
它在哪里丢分?
最大的下降来自代理接口和身份认证,这两项都是零分(满分100)——意味着Notion对遵循现代发现协议的代理是不可见的。
该如何修复?
三个有针对性的改进可以让Notion从一个被动抓取的网络资源转变为代理网络的主动参与者。
在robots.txt中声明AI爬虫规则
为AI爬虫提供明确的权限或限制规则,以便他们知道可以索引和引用哪些路径。
robots.txt不包含GPTBot、ClaudeBot、PerplexityBot或任何其他AI爬虫的user-agent块。
为每个主要AI爬虫添加专用的User-agent块,后跟Allow或Disallow指令。对于公开的营销和帮助内容,使用Allow /;对于您不想被引用的私人工作区路径,添加相应的Disallow行。
发布MCP服务器卡
向遵循Model Context Protocol发现标准的AI代理公开Notion的功能。
标准发现路径中不存在MCP服务器卡,使得agent_interfaces为零。
在/.well-known/mcp/server-card.json提供JSON文档,列出serverInfo、传输端点和可用功能,如页面读取、数据库查询和块创建。这使MCP兼容的代理能够直接集成,无需手动配置。
为代理请求返回Markdown
当代理表示更喜欢机器可读的文本而不是HTML时,以干净的Markdown形式传递页面内容。
网站无论Accept头如何都返回HTML,所以请求text/markdown的代理会收到一个排版复杂的文档而不是纯内容。
在公开页面上检测Accept: text/markdown请求头,并返回Content-Type: text/markdown的Markdown渲染。保持HTML作为浏览器的默认值。这让AI代理可以摄取Notion的帮助文档和营销内容,无需DOM解析。
常见问题
Notion的AEO评分43分(满分100)实际上意味着什么?
尽管评分较低,AI代理今天还能使用Notion内容吗?
哪个修复对Notion的AEO评分影响最快?
你自己的网站为 AI 做好准备了吗?
对任意网址运行同样的五类别分析。免费,开始无需注册。
免费检测你的网站