AI 如何读取 Cava
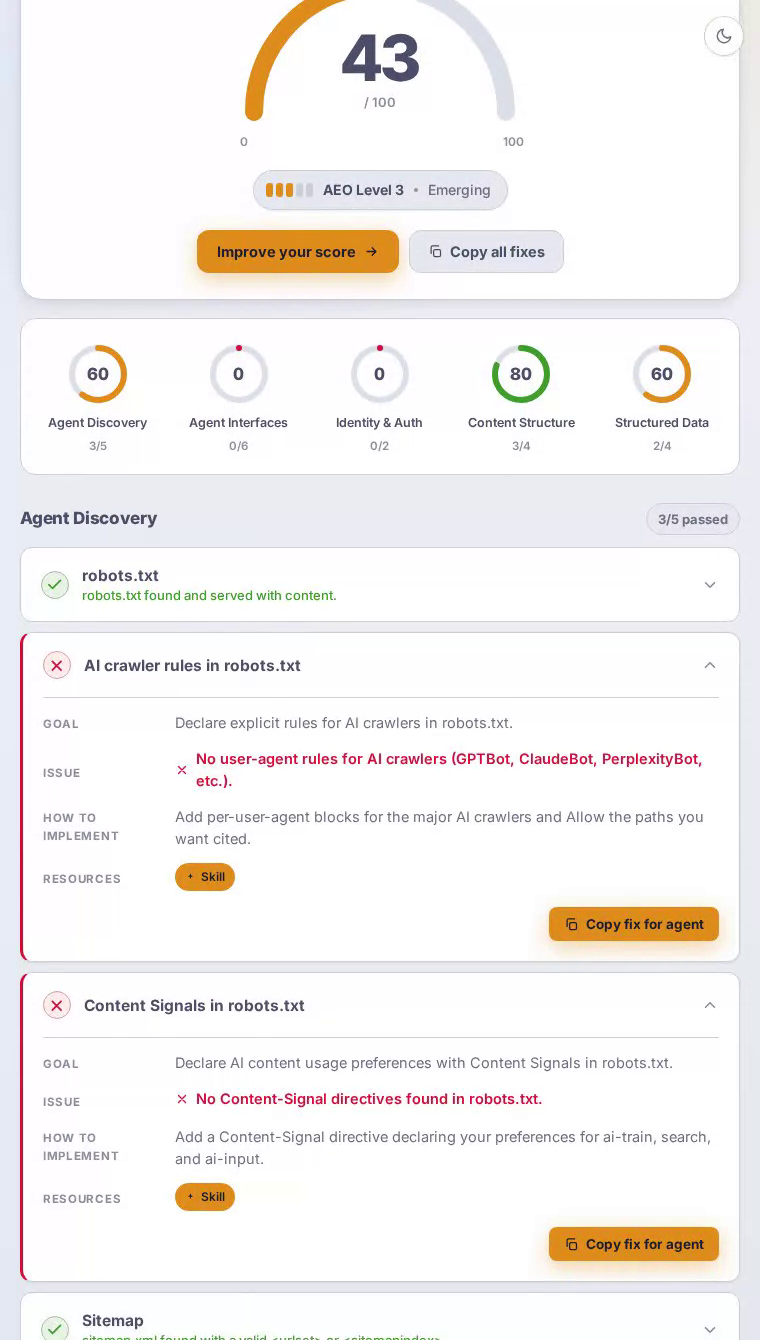
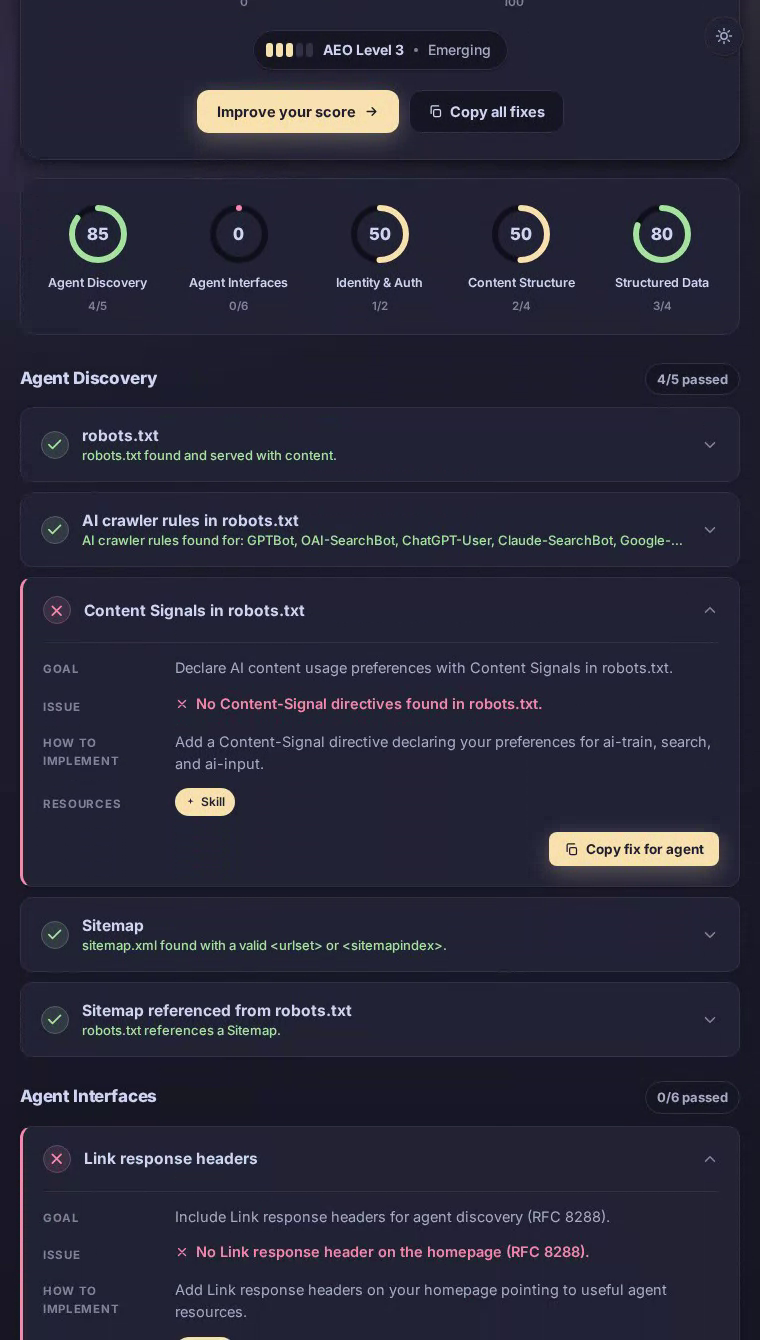
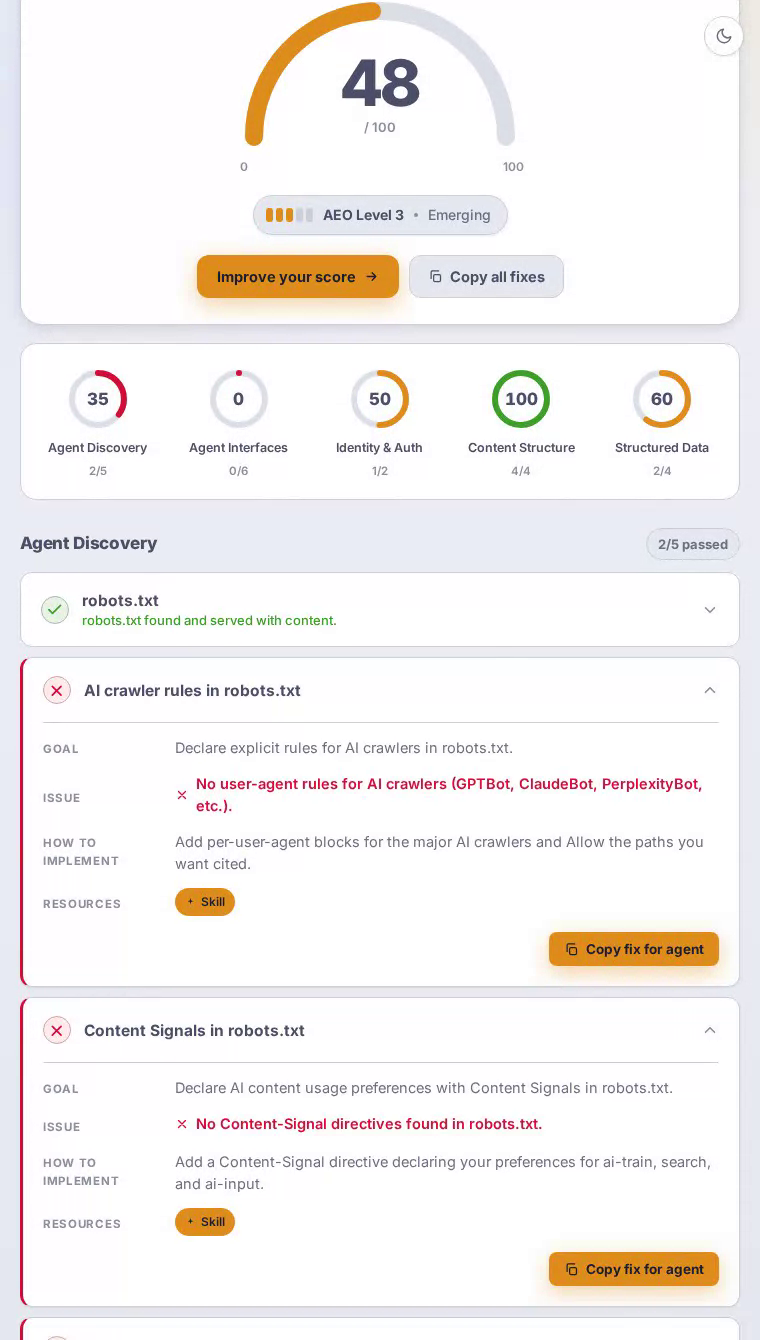
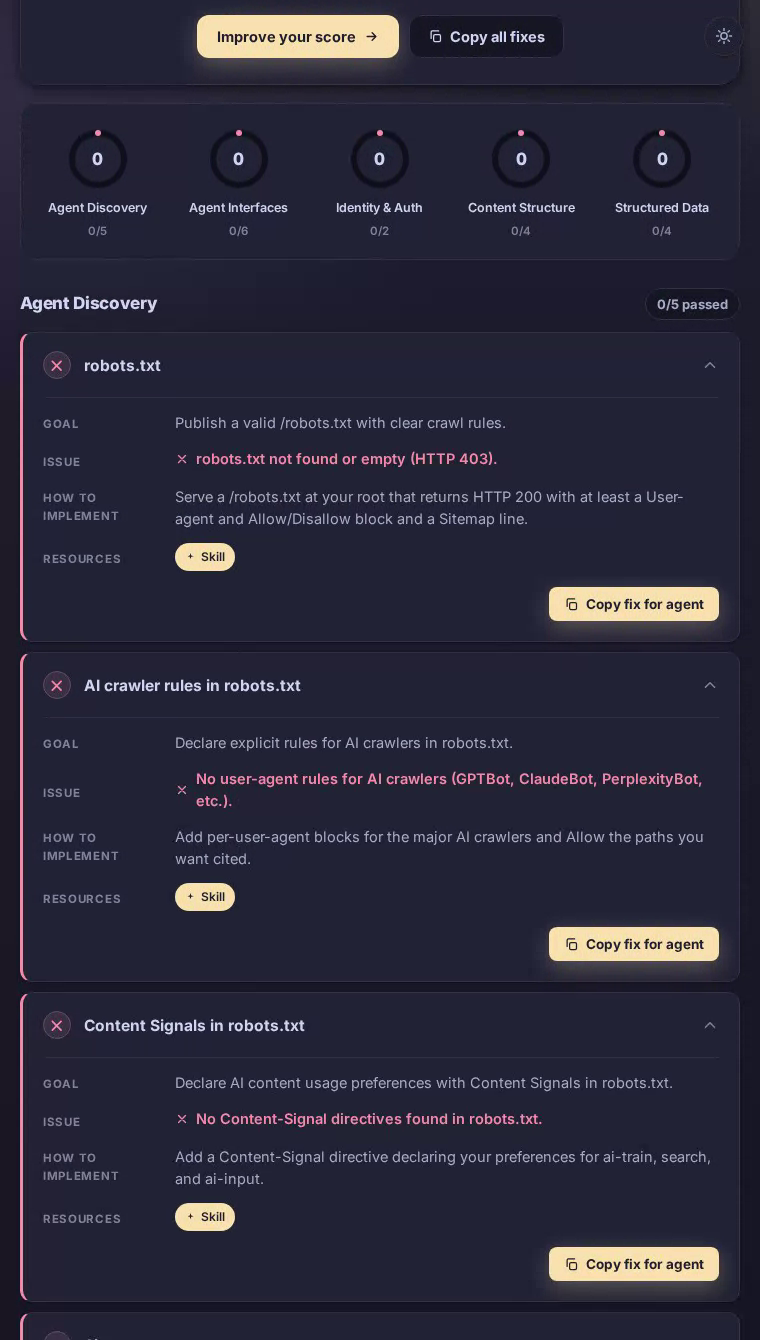
Cava在我们的AEO扫描中获得0分,在所有五个类别中获得最低评分。这家快餐地中海连锁餐厅为robots.txt和sitemap.xml都主动返回HTTP 403错误,使AI答案引擎和自主代理无法从其菜单、位置或营养内容中获得结构化访问路径。
AI 看到了什么?
当AI代理访问Cava主页时,它遇到了客户端渲染视觉效果的墙,下面没有机器可读的访问层。
AI爬虫来到Cava主页时会遇到看起来是一种精美、现代的餐厅体验——但AI系统依赖的基础设施不存在。robots.txt端点返回HTTP 403,许多爬虫将其解释为隐性的全面屏蔽。没有站点地图来枚举位置页面、碗定制或营养指南。没有针对GPTBot、ClaudeBot或PerplexityBot的显式用户代理规则。实际后果是:当注重健康的用餐者向AI助手询问低卡路里的地中海快餐选项,或查询Cava的成分采购和过敏原政策时,该品牌对这些系统没有结构化的存在。这些本应产生转化的高意图时刻被错失了。
它在哪里丢分?
代理发现——决定AI系统能否到达网站的基础层——获得零分,这个失败级联到其他每个类别。
该如何修复?
三个基础设施变更,都不需要内容改写,会使Cava从完全不可见变为主动可索引。
解除封锁并提供有效的robots.txt
从/robots.txt返回HTTP 200,以便AI爬虫可以读取网站的访问规则,而不是将其视为禁止。
扫描发现robots.txt返回HTTP 403,许多爬虫将其视为全面拒绝访问。
在域根目录部署/robots.txt,返回HTTP 200,并至少包含User-agent块、Allow或Disallow指令以及具有绝对站点地图URL的Sitemap行。这个文件是其他每个发现机制正常工作的先决条件。
发布sitemap.xml并引用它
为AI爬虫提供Cava菜单页面、位置列表和营养内容的结构化索引。
sitemap.xml也返回HTTP 403,使代理无法枚举Cava数百个位置页面或菜单类别。
生成/sitemap.xml,列出优先级URL——菜单类别、单个位置页面、营养数据——带有lastmod时间戳,以application/xml形式提供。然后在robots.txt中添加Sitemap:指令,指向其绝对URL,以便爬虫在首次访问时自动发现它。
添加显式AI爬虫用户代理规则
为主要AI系统声明每个代理的权限,以便答案引擎对其可能引用的内容有权威指导。
在网站配置中没有发现针对GPTBot、ClaudeBot、PerplexityBot或任何其他AI爬虫的用户代理块。
在robots.txt中,为GPTBot、ClaudeBot、PerplexityBot和Googlebot-Extended添加单独的User-agent块,每个块后跟Allow: / 用于要引用的路径——成分列表、碗定制页面、餐饮服务选项、门店查询结果。显式权限是出现在AI生成的用餐建议中的最快方式。
常见问题
尽管Cava是一家全国公认的餐厅连锁店,为什么它在AEO上获得0/100分?
Cava通过AI答案引擎无法显示什么具体内容?
Cava在修复这些问题后能多快改善其AEO评分?
你自己的网站为 AI 做好准备了吗?
对任意网址运行同样的五类别分析。免费,开始无需注册。
免费检测你的网站