AI 如何读取 Dropbox
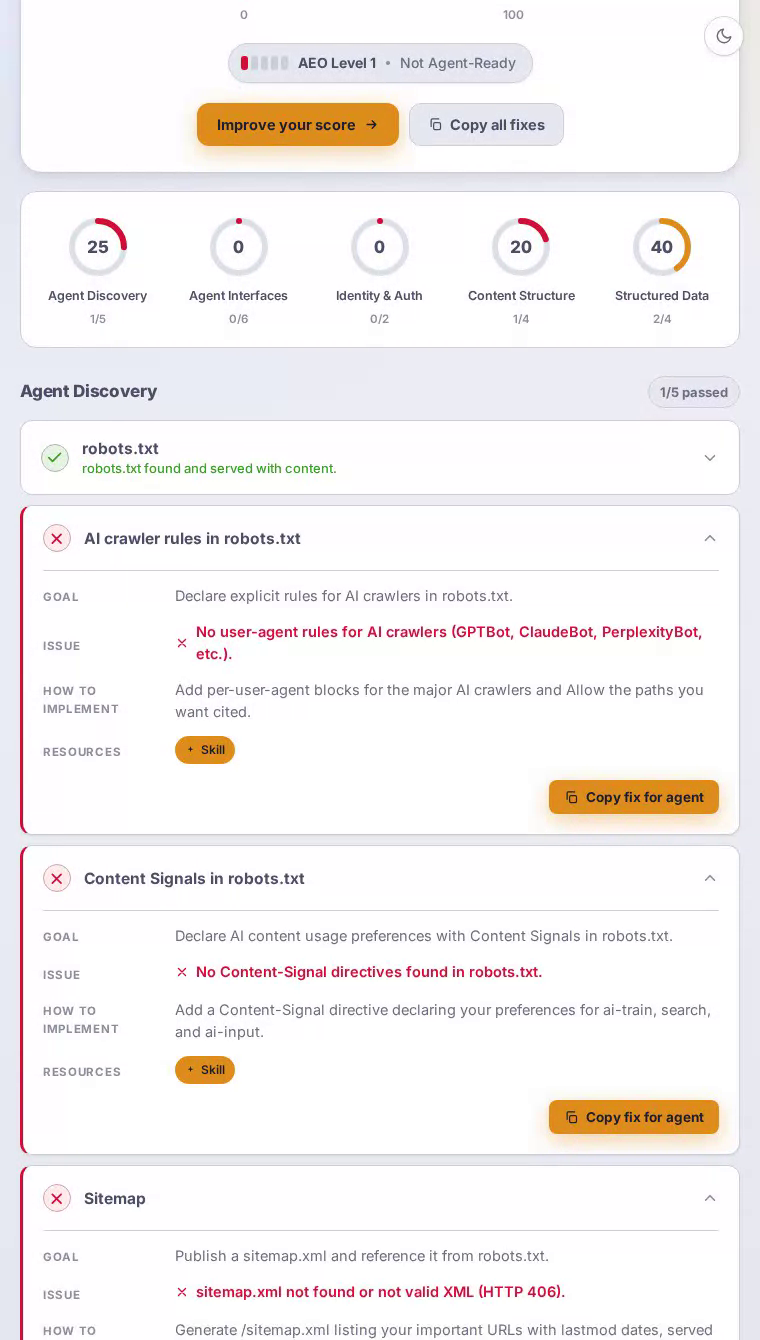
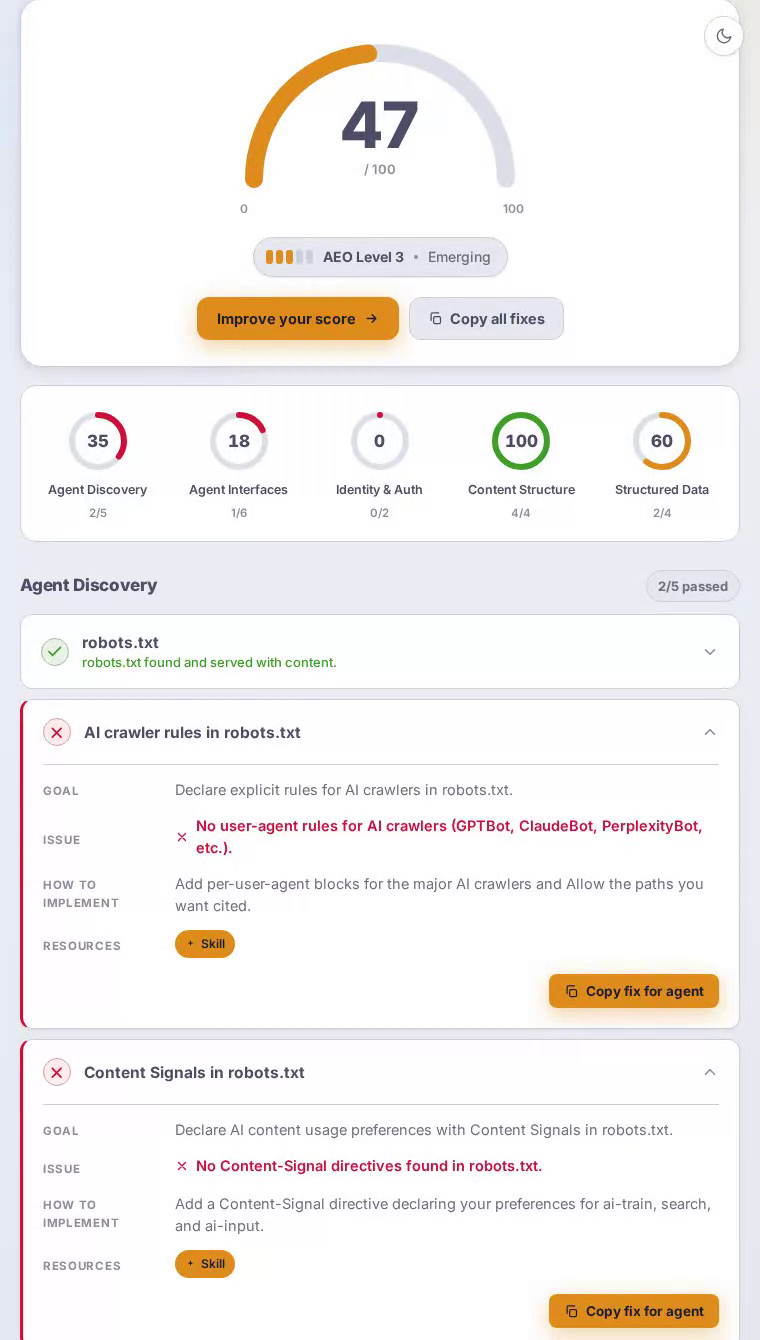
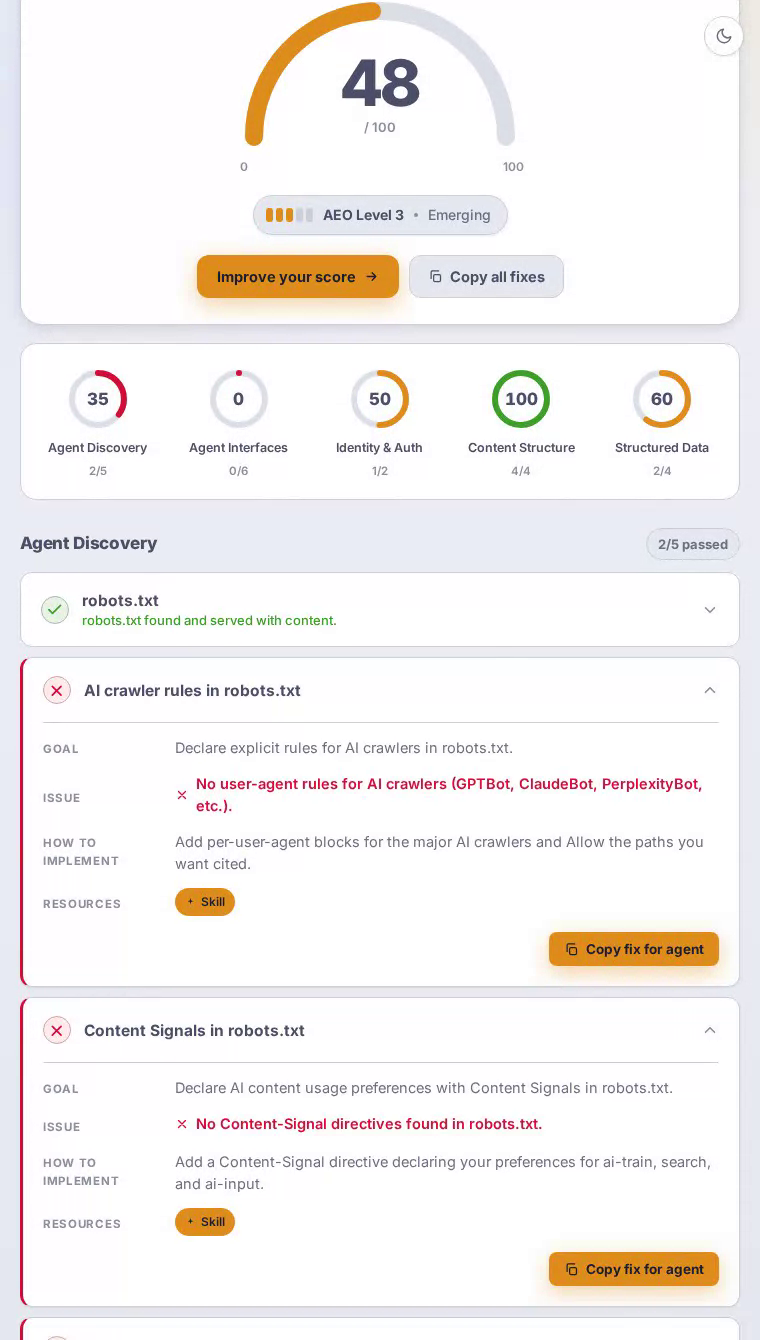
Dropbox 在 AEO 扫描中得分 48 分(满分 100)。其 HTML 和语义标记完美无缺,但完全缺乏 agent interfaces——没有 MCP card、API catalog 和 Markdown endpoint——意味着研究云存储工具的 AI 助手从 Dropbox 获得的信号远少于其品牌规模所应有的。
AI 看到了什么?
当 AI 爬虫访问 Dropbox 主页时,它会遇到精心打磨的营销 HTML,但下方没有机器可读的发现层。
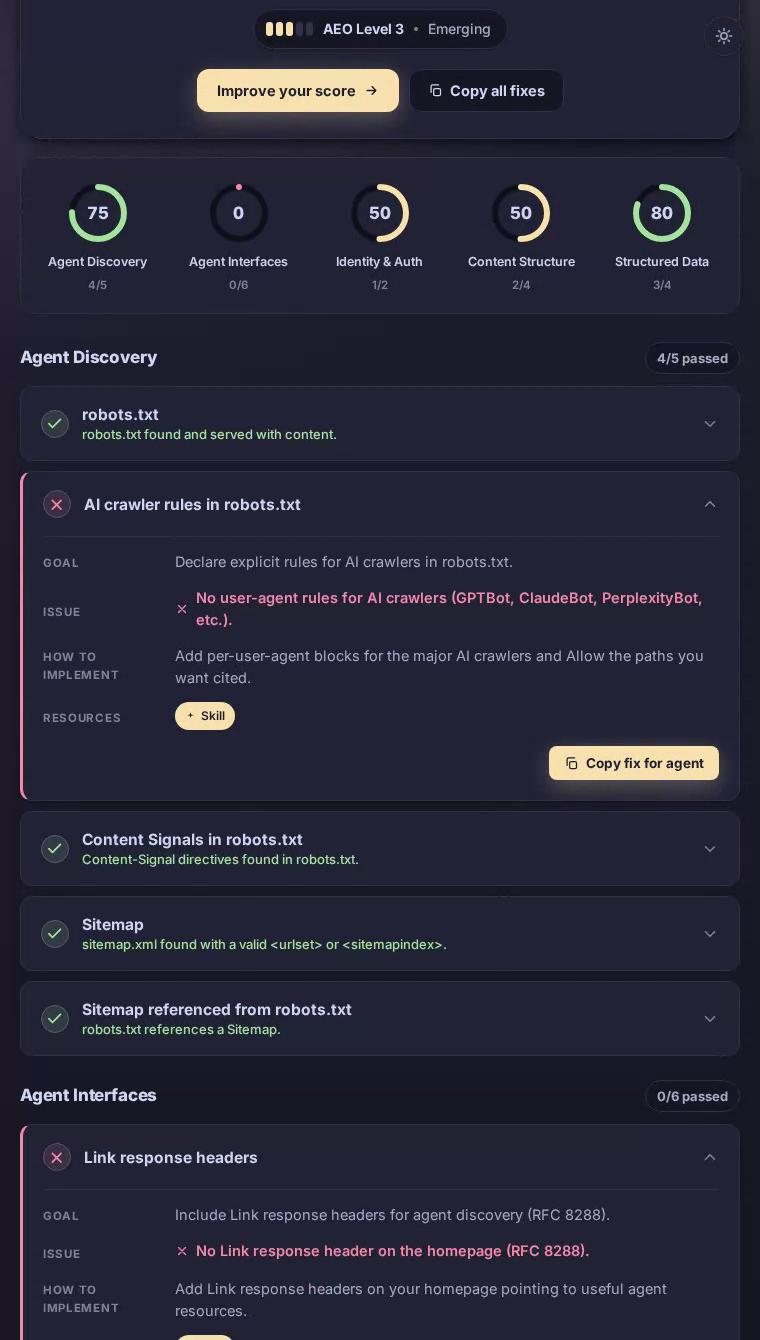
主页提供了格式正确的 HTML,具有清晰的标题层级,结构化数据为面向搜索的 agent 提供了足够的上下文来理解产品类别——内容结构得分完美的 100/100。但 robots.txt 没有为 GPTBot、ClaudeBot 或 PerplexityBot 制定明确规则,因此 AI 爬虫只能凭猜测运行。sitemap.xml 返回 404,完全阻止了系统性内容发现。没有 Link 响应头指向 agent 访问 API 或备用表示。而且由于服务器无论 Accept 头如何都总是返回 HTML,请求 Markdown 的 agent 会两手空空离开——这对于其核心价值主张是管理和共享大规模内容的平台来说是一个重大失误。
它在哪里丢分?
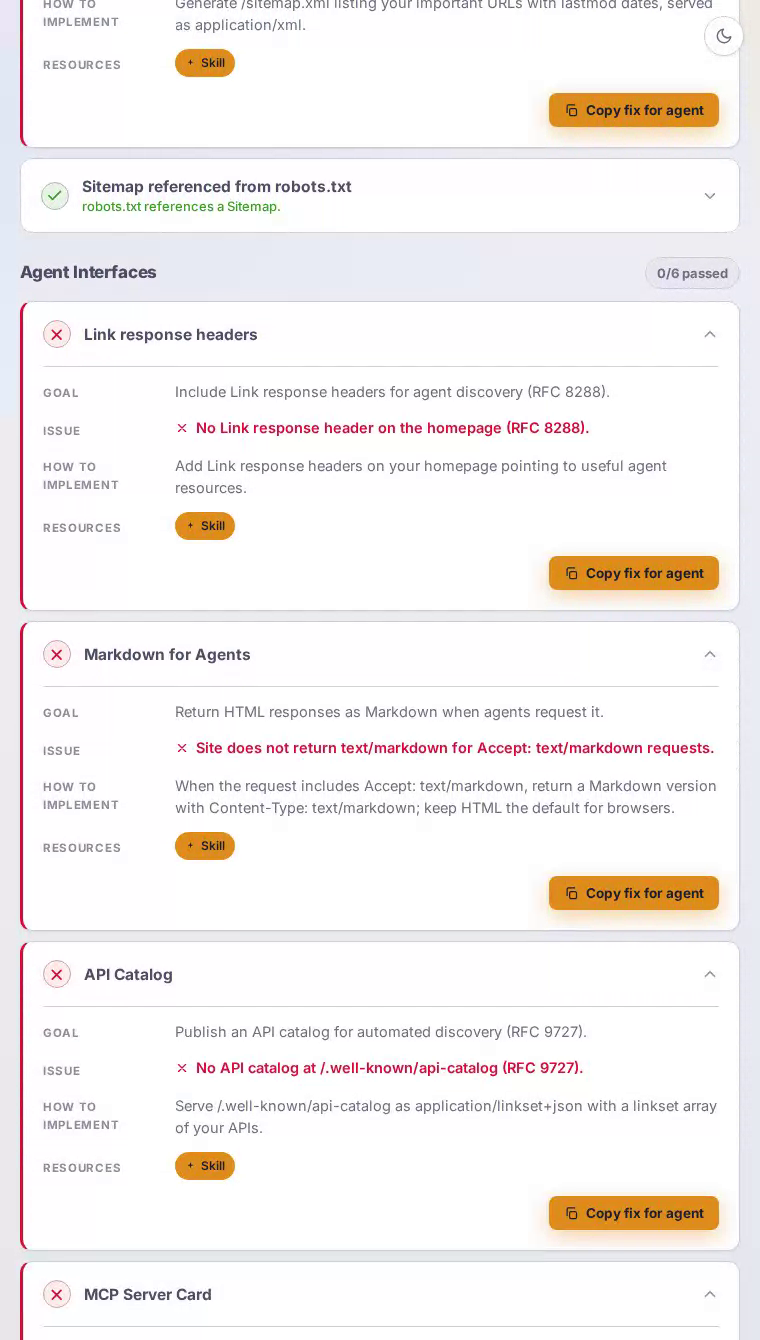
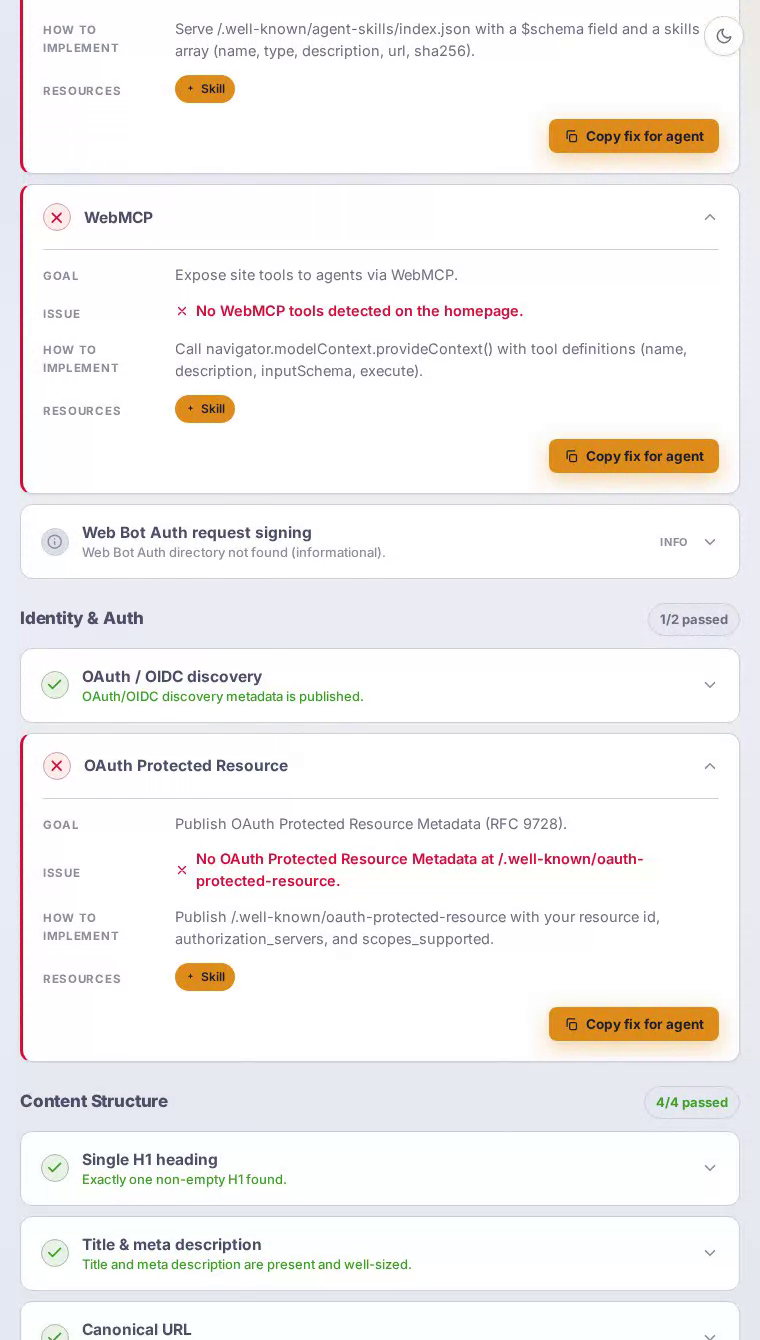
Agent interfaces 是 Dropbox 最困难的失败,得分为零——该类别中的每项检查都未通过。
该如何修复?
三项有针对性的补充将弥补最大的差距,使 Dropbox 对 AI agent 和答案引擎更具可读性。
在 robots.txt 中添加 AI 爬虫规则
声明明确的每个 agent 规则,以便 GPTBot、ClaudeBot 和 PerplexityBot 确切知道哪些路径它们可以和不可以索引。
当前的 robots.txt 对任何主要 AI 爬虫都没有 user-agent 条目,因此每个爬虫都会回退到默认行为,而 Dropbox 没有提供任何指导。
为 GPTBot、ClaudeBot、PerplexityBot 和其他主要 AI 爬虫添加单独的 User-agent 块,然后指定 Allow 和 Disallow 路径。后面加上 Content-Signal 指令,声明对 ai-train、search 和 ai-input 的偏好,以便模型运营商了解 Dropbox 对训练数据使用的立场。
发布有效的 sitemap.xml
为 AI 爬虫和搜索引擎提供重要网址的结构化映射,包含新鲜度信号。
扫描发现 sitemap.xml 返回 HTTP 404——这对于 Dropbox 这样规模的平台和全球流量来说是一个意外的缺陷。
生成列出产品、支持和博客网址的 /sitemap.xml,带有 lastmod 时间戳,以 application/xml 格式提供。从 robots.txt 使用 Sitemap 指令引用它,以便每个爬虫在首次访问时自动找到它。
在 /.well-known/api-catalog 发布 API 目录
通过标准化的 RFC 9727 endpoint 启用 Dropbox 开发者 API 的自动 agent 发现。
在 /.well-known/api-catalog 不存在 API 目录,导致与云存储集成的 agent 没有标准化路径来查找和连接到 Dropbox API。
将 /.well-known/api-catalog 作为 application/linkset+json 提供,包含描述核心 Dropbox API 和 Paper API 的 linkset 数组。将其与 /.well-known/mcp/server-card.json 配对,以便 MCP 兼容的 agent 可以协商直接集成,无需手动配置。
常见问题
尽管 Dropbox 是全球最知名的云平台之一,为什么它的得分只有 48/100?
如果没有这些修复,ChatGPT 或 Claude 等 AI 助手会推荐 Dropbox 吗?
对于 Dropbox 这样的网站,缺少 sitemap.xml 有多重要?
你自己的网站为 AI 做好准备了吗?
对任意网址运行同样的五类别分析。免费,开始无需注册。
免费检测你的网站