How AI reads Dropbox
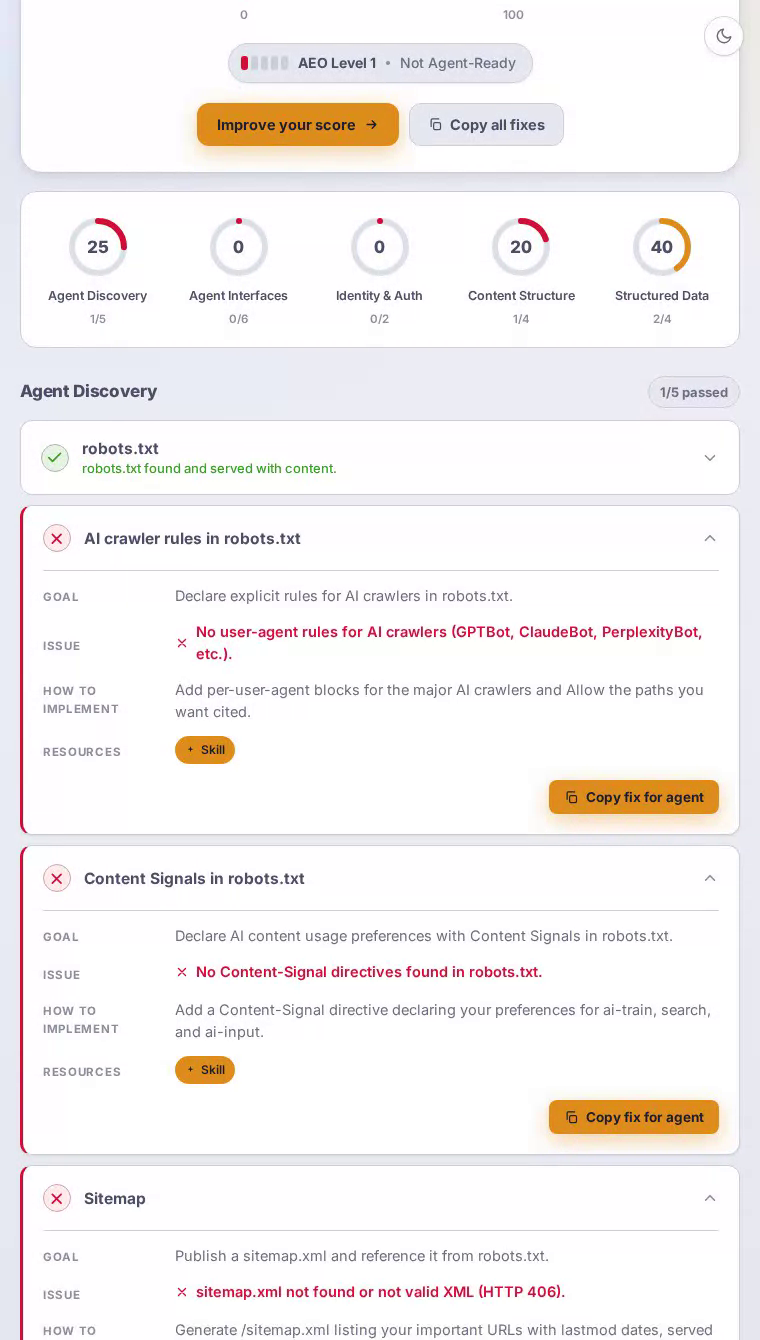
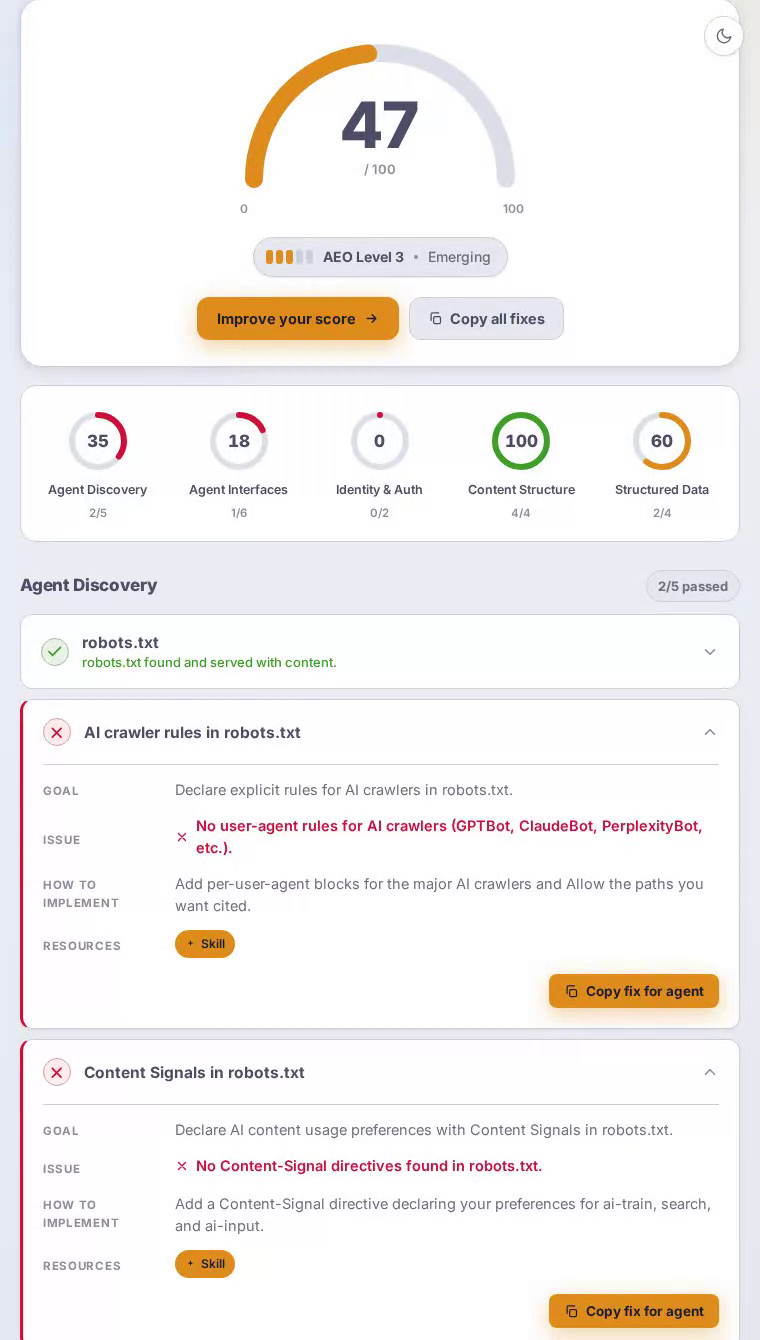
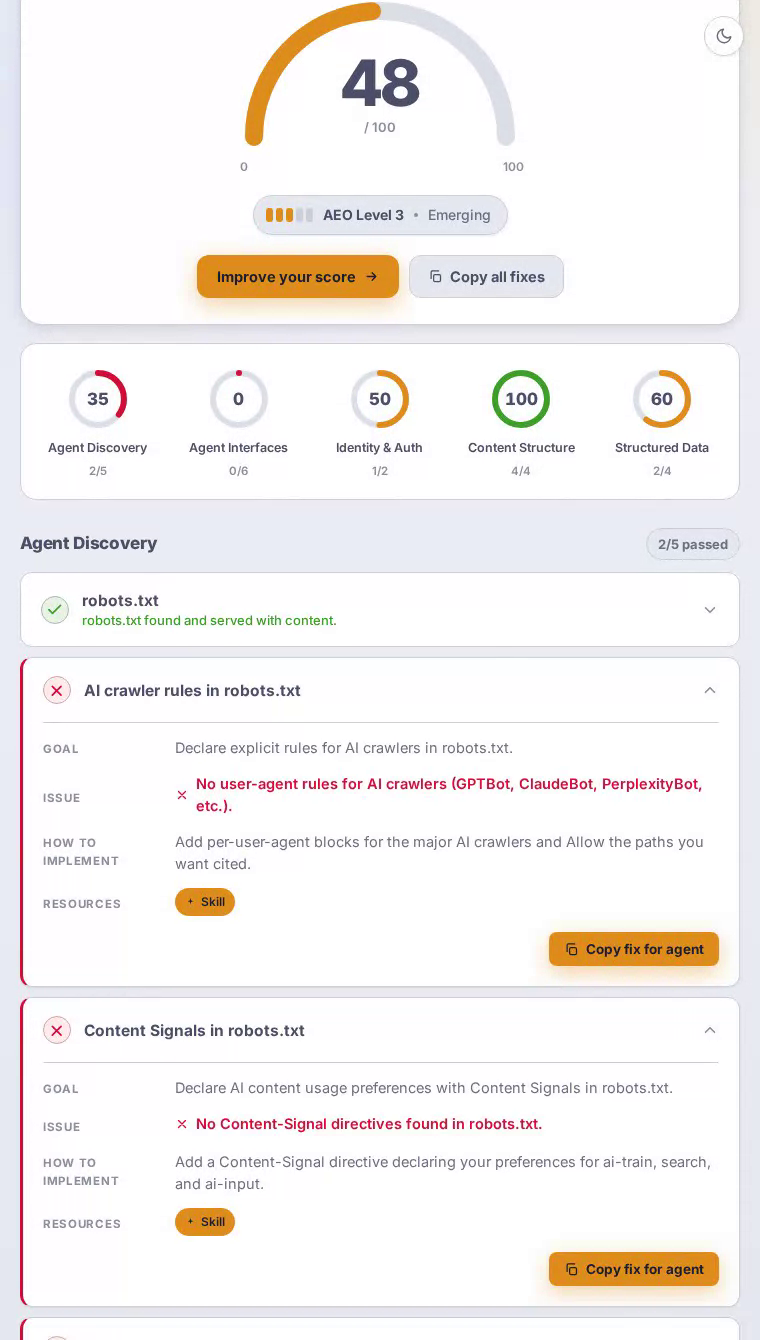
Dropbox scores 48 out of 100 in our AEO scan. Its HTML and semantic markup are flawless, but a complete absence of agent interfaces — no MCP card, no API catalog, no Markdown endpoint — means AI assistants researching cloud storage tools get far less signal from Dropbox than the brand's scale deserves.
What AI sees
When an AI crawler visits the Dropbox homepage today, it encounters polished marketing HTML with no machine-readable discovery layer underneath.
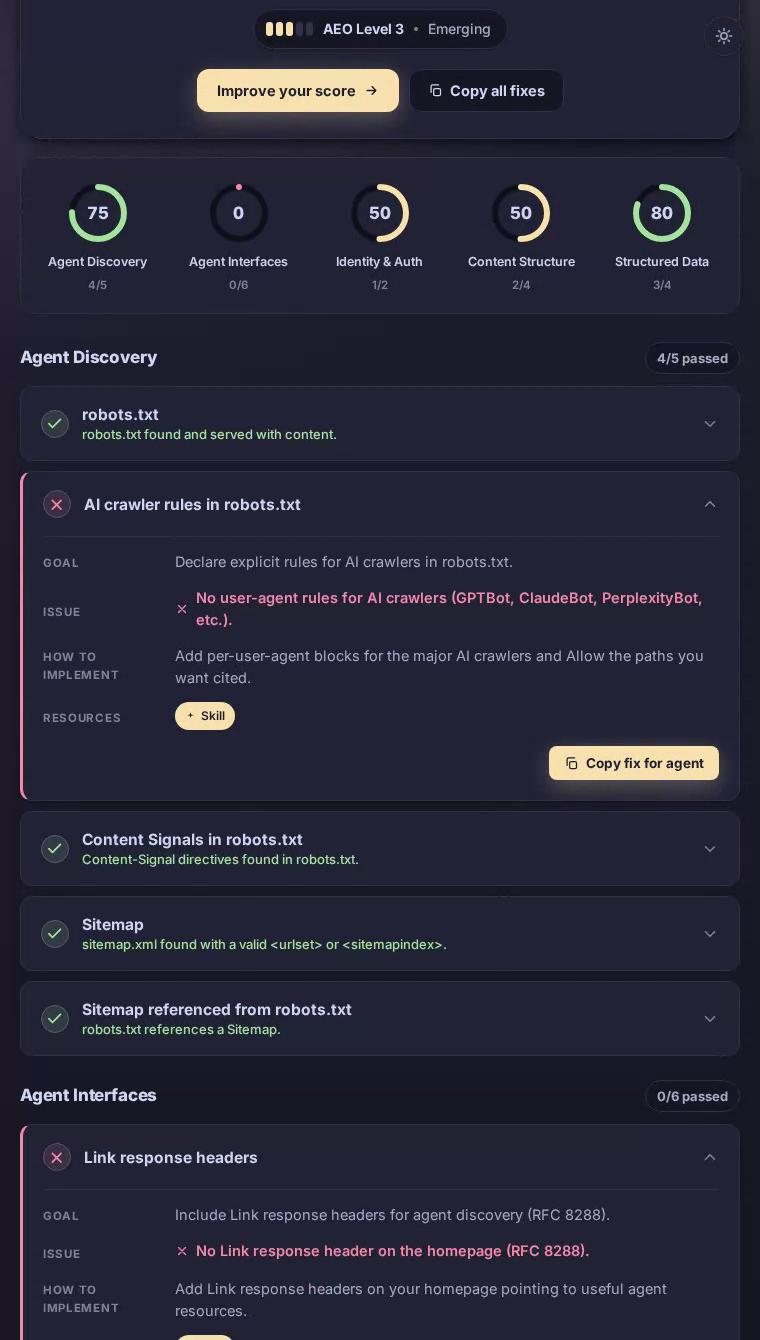
The homepage delivers well-formed HTML with a solid heading hierarchy, and structured data gives search-oriented agents enough context to understand the product category — content structure scores a perfect 100 out of 100. But robots.txt carries no explicit rules for GPTBot, ClaudeBot, or PerplexityBot, so AI crawlers operate on guesswork. The sitemap.xml returns a 404, blocking systematic content discovery entirely. No Link response headers point agents toward APIs or alternate representations. And because the server always returns HTML regardless of the Accept header, agents that request Markdown walk away empty-handed — a critical miss for a platform whose core value proposition is managing and sharing content at scale.
Where it loses points
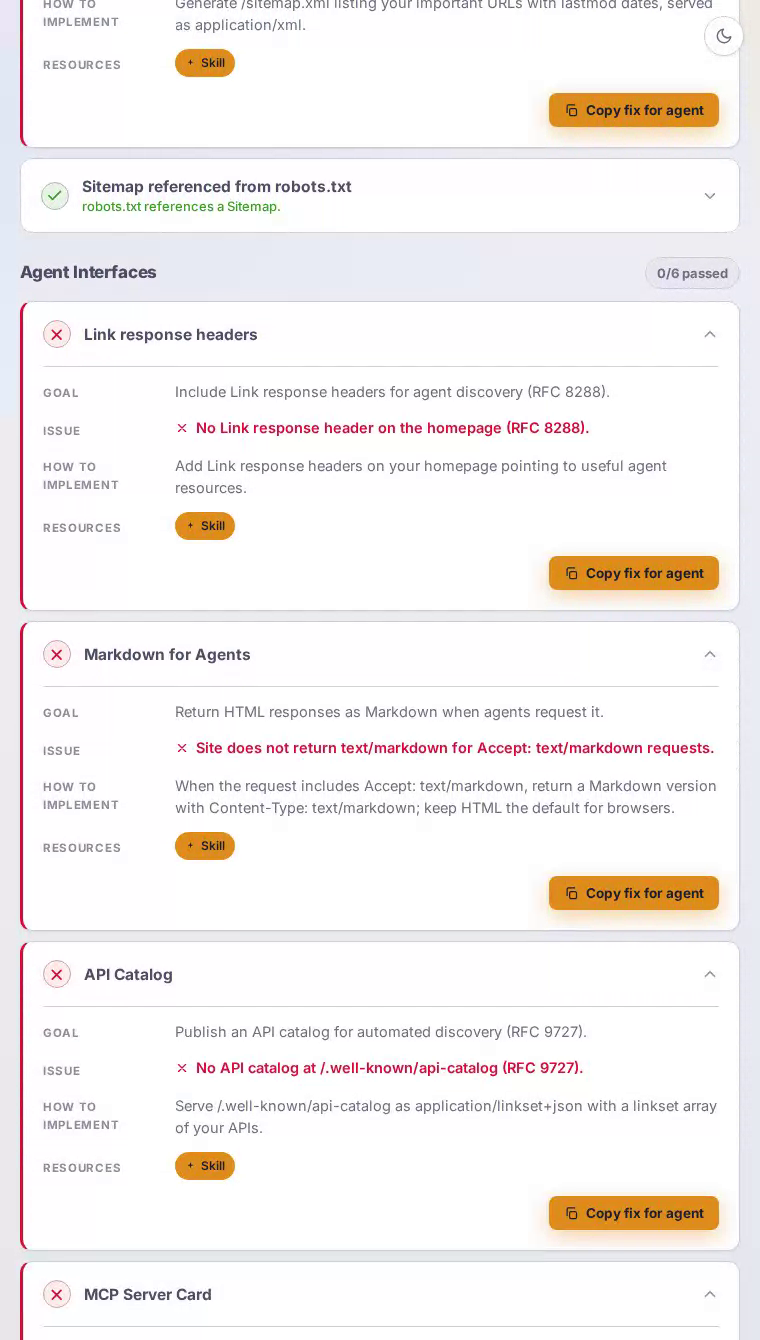
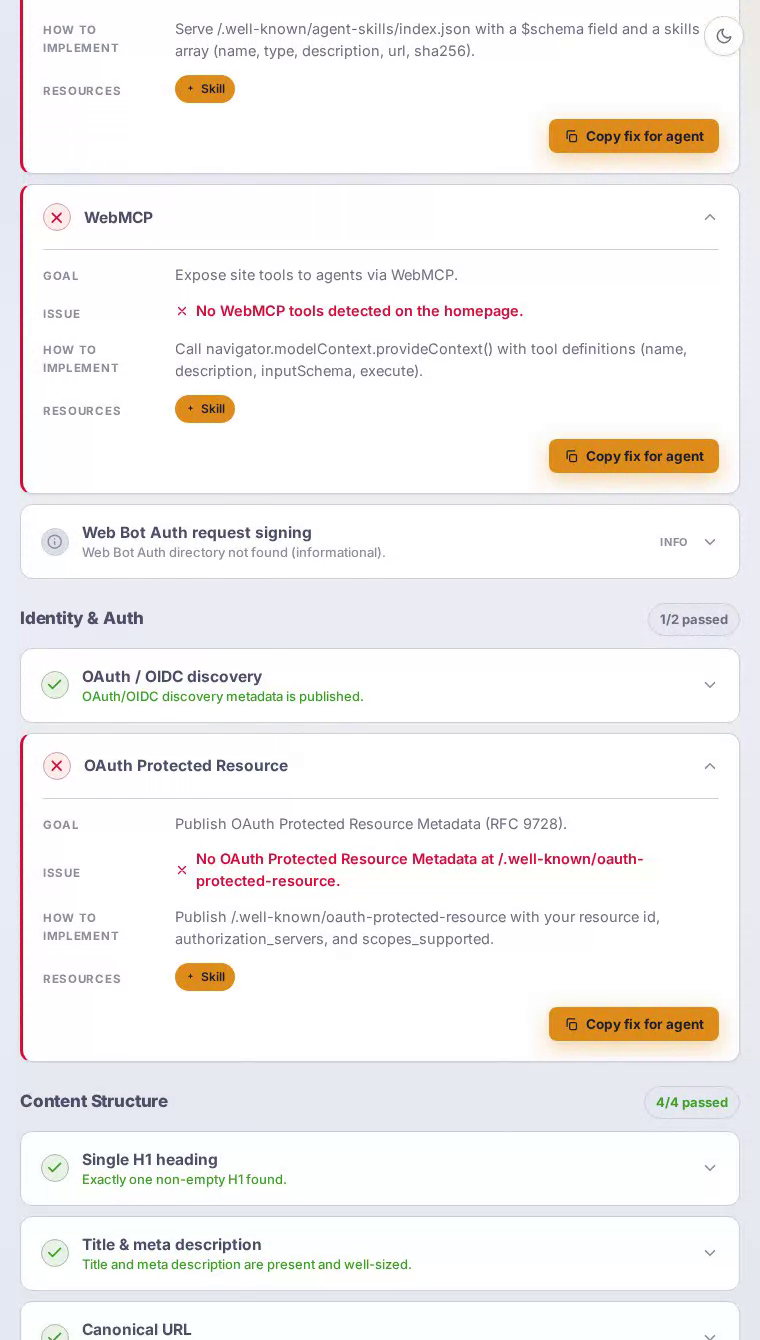
Agent interfaces is Dropbox's hardest failure, scoring a flat zero — every single check in that category is unmet.
How to fix it
Three targeted additions would close the biggest gaps and make Dropbox meaningfully more legible to AI agents and answer engines.
Add AI crawler rules to robots.txt
Declare explicit per-agent rules so GPTBot, ClaudeBot, and PerplexityBot know exactly which paths they may and may not index.
The current robots.txt has no user-agent entries for any major AI crawler, so each crawler falls back to default behaviour with no guidance from Dropbox.
Add individual User-agent blocks for GPTBot, ClaudeBot, PerplexityBot, and other leading AI crawlers, then specify Allow and Disallow paths. Follow with a Content-Signal directive declaring preferences for ai-train, search, and ai-input so model operators know Dropbox's stance on training data use.
Publish a valid sitemap.xml
Give AI crawlers and search engines a structured map of important URLs with freshness signals.
The scan found sitemap.xml returns HTTP 404 — an unexpected gap for a platform of Dropbox's size and global traffic volume.
Generate /sitemap.xml listing product, support, and blog URLs with lastmod timestamps, served as application/xml. Reference it from robots.txt with a Sitemap directive so every crawler finds it automatically on its first visit.
Publish an API catalog at /.well-known/api-catalog
Enable automated agent discovery of Dropbox's developer APIs through the standardised RFC 9727 endpoint.
No API catalog exists at /.well-known/api-catalog, leaving agents that integrate with cloud storage no standardised path to find and connect to the Dropbox API.
Serve /.well-known/api-catalog as application/linkset+json with a linkset array describing the core Dropbox API and Paper API. Pair it with a /.well-known/mcp/server-card.json so MCP-compatible agents can negotiate a direct integration without manual configuration.
Common questions
Why does Dropbox score only 48/100 despite being one of the world's most recognised cloud platforms?
Will AI assistants like ChatGPT or Claude recommend Dropbox without these fixes?
How much does a missing sitemap.xml matter for a site like Dropbox?
Is your own site ready for AI?
Run the same five-category analysis on any URL. Free, no account needed to start.
Check your own website free