How AI reads Cava
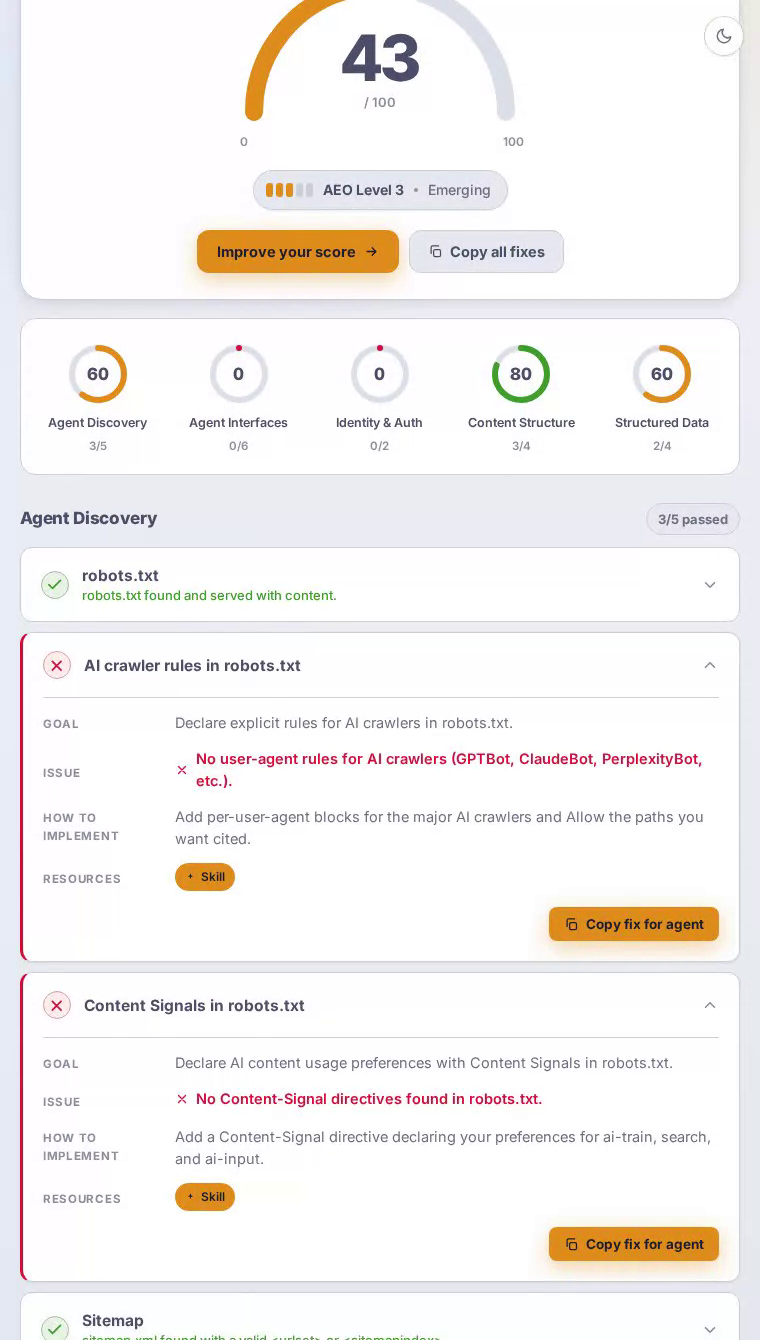
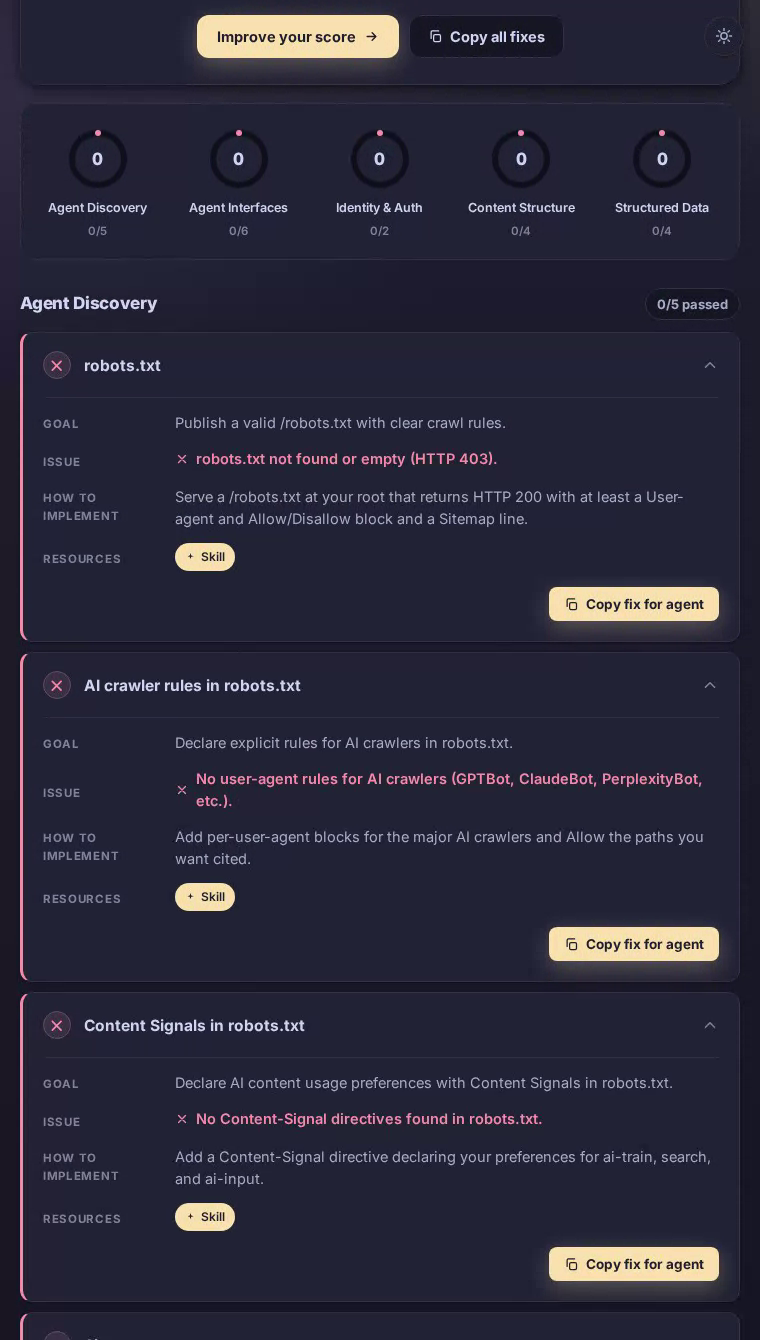
Cava scored 0 out of 100 in our AEO scan — the lowest possible rating across all five categories. The fast-casual Mediterranean chain actively returns HTTP 403 errors for both robots.txt and sitemap.xml, leaving AI answer engines and autonomous agents with no structured pathway into its menu, locations, or nutritional content.
What AI sees
When an AI agent visits Cava's homepage today, it hits a wall of client-rendered visuals with no machine-readable access layer beneath.
An AI crawler arriving at Cava's homepage encounters what appears to be a polished, modern restaurant experience — but the infrastructure AI systems rely on is absent. The robots.txt endpoint returns HTTP 403, a status that many crawlers interpret as an implicit blanket block. There is no sitemap to enumerate location pages, bowl customizations, or nutritional guides. No explicit user-agent rules exist for GPTBot, ClaudeBot, or PerplexityBot. The practical consequence: when health-conscious diners ask AI assistants about low-calorie Mediterranean fast-casual options, or query Cava's ingredient sourcing and allergen policies, the brand has no structured presence for those systems to draw from. High-intent moments that should convert go unserved.
Where it loses points
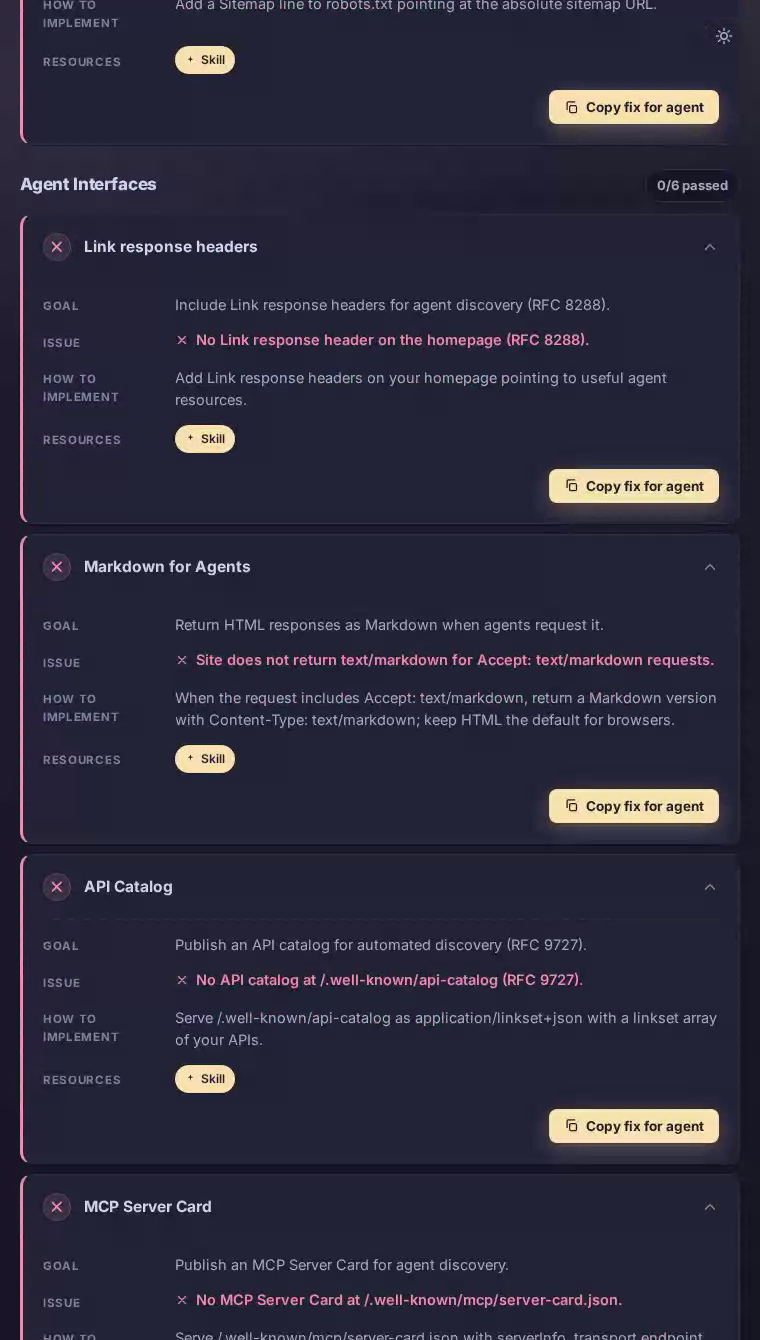
Agent discovery — the baseline layer that determines whether AI systems can reach a site at all — scored zero, and that failure cascades across every other category.
How to fix it
Three infrastructure changes, none requiring a content overhaul, would move Cava from completely invisible to actively indexable.
Unblock and serve a valid robots.txt
Return HTTP 200 from /robots.txt so AI crawlers can read the site's access rules instead of treating it as forbidden.
The scan found robots.txt returning HTTP 403, which many crawlers treat as a blanket denial of access.
Deploy a /robots.txt at the domain root that serves HTTP 200 and contains at minimum a User-agent block, an Allow or Disallow directive, and a Sitemap line with the absolute sitemap URL. This single file is the prerequisite for every other discovery mechanism to function.
Publish a sitemap.xml and reference it
Give AI crawlers a structured index of Cava's menu pages, location listings, and nutritional content.
sitemap.xml also returns HTTP 403, leaving agents with no way to enumerate Cava's hundreds of location pages or menu categories.
Generate /sitemap.xml listing priority URLs — menu categories, individual location pages, nutritional data — with lastmod timestamps, served as application/xml. Then add a Sitemap: directive inside robots.txt pointing to its absolute URL so crawlers discover it automatically on their first visit.
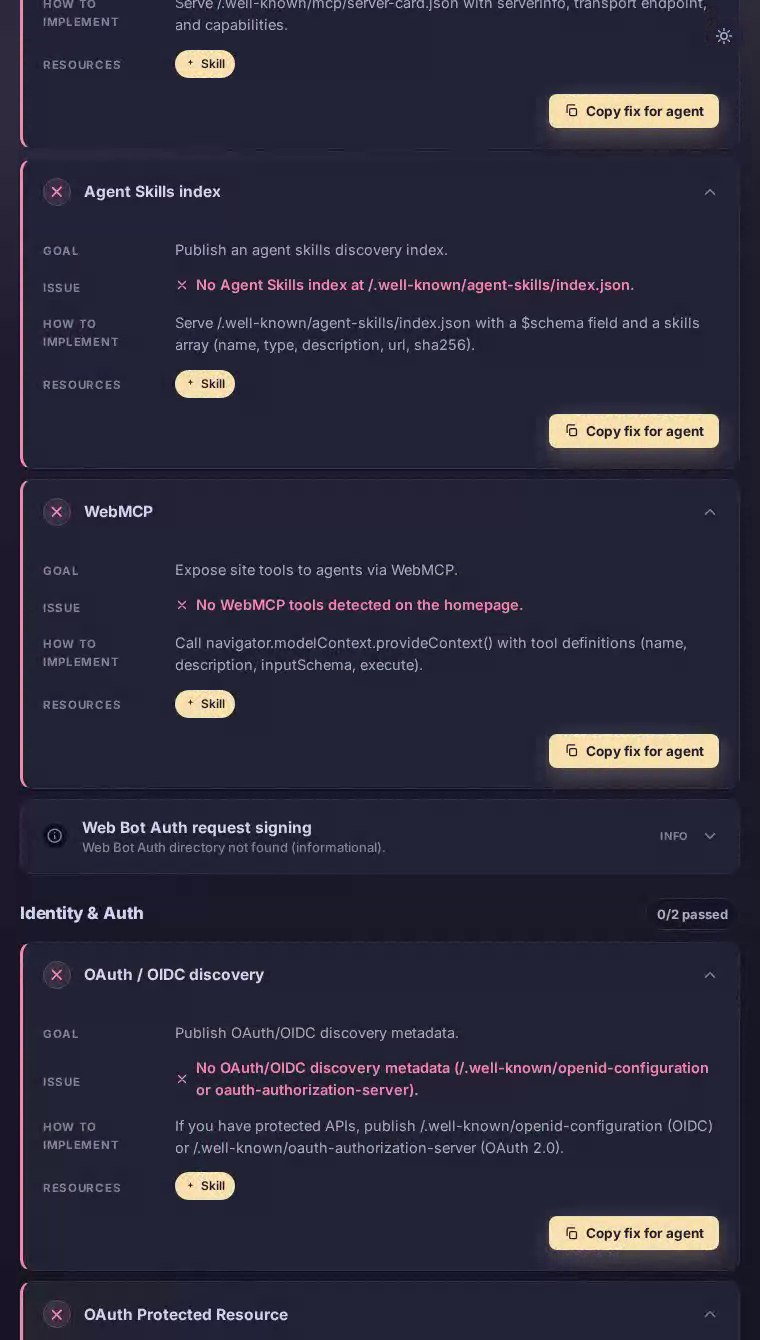
Add explicit AI-crawler user-agent rules
Declare per-agent permissions for the major AI systems so answer engines have authoritative guidance on what they may cite.
No user-agent blocks for GPTBot, ClaudeBot, PerplexityBot, or any other AI crawler were found in the site's configuration.
Inside robots.txt, add individual User-agent blocks for GPTBot, ClaudeBot, PerplexityBot, and Googlebot-Extended, each followed by Allow: / for paths you want cited — ingredient lists, bowl builder pages, catering options, store locator results. Explicit permission is the fastest way to appear in AI-generated dining recommendations.
Common questions
Why does Cava score 0/100 on AEO despite being a nationally recognized restaurant chain?
What specific content is Cava missing out on surfacing through AI answer engines?
How quickly could Cava improve its AEO score after fixing these issues?
Is your own site ready for AI?
Run the same five-category analysis on any URL. Free, no account needed to start.
Check your own website free